- Schema Book
- Topics
Topics
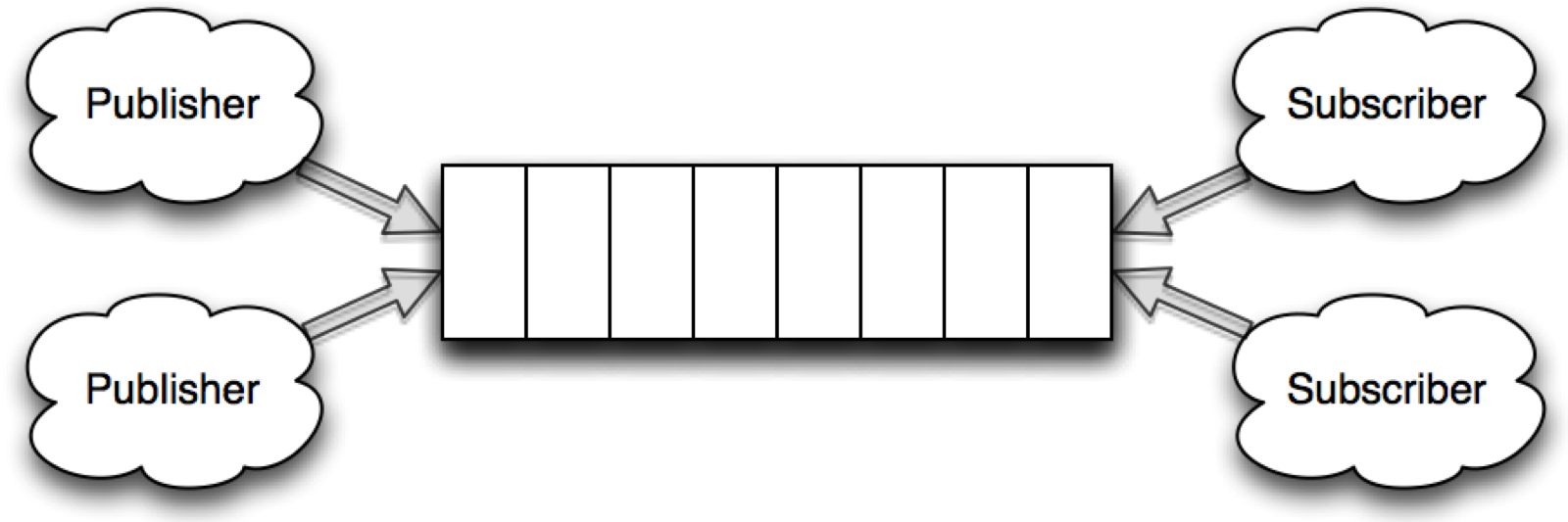
A topic-based system is one where messages are published to a named channel (topics) to one or more subscribers. The difference from a queue is that all subscribers receive the same message.
MongoDB has a special type of collection called a capped collection, and a special type of cursor called a tailable cursor, that lets you simply and elegantly model a topic-based publish and subscribe system.
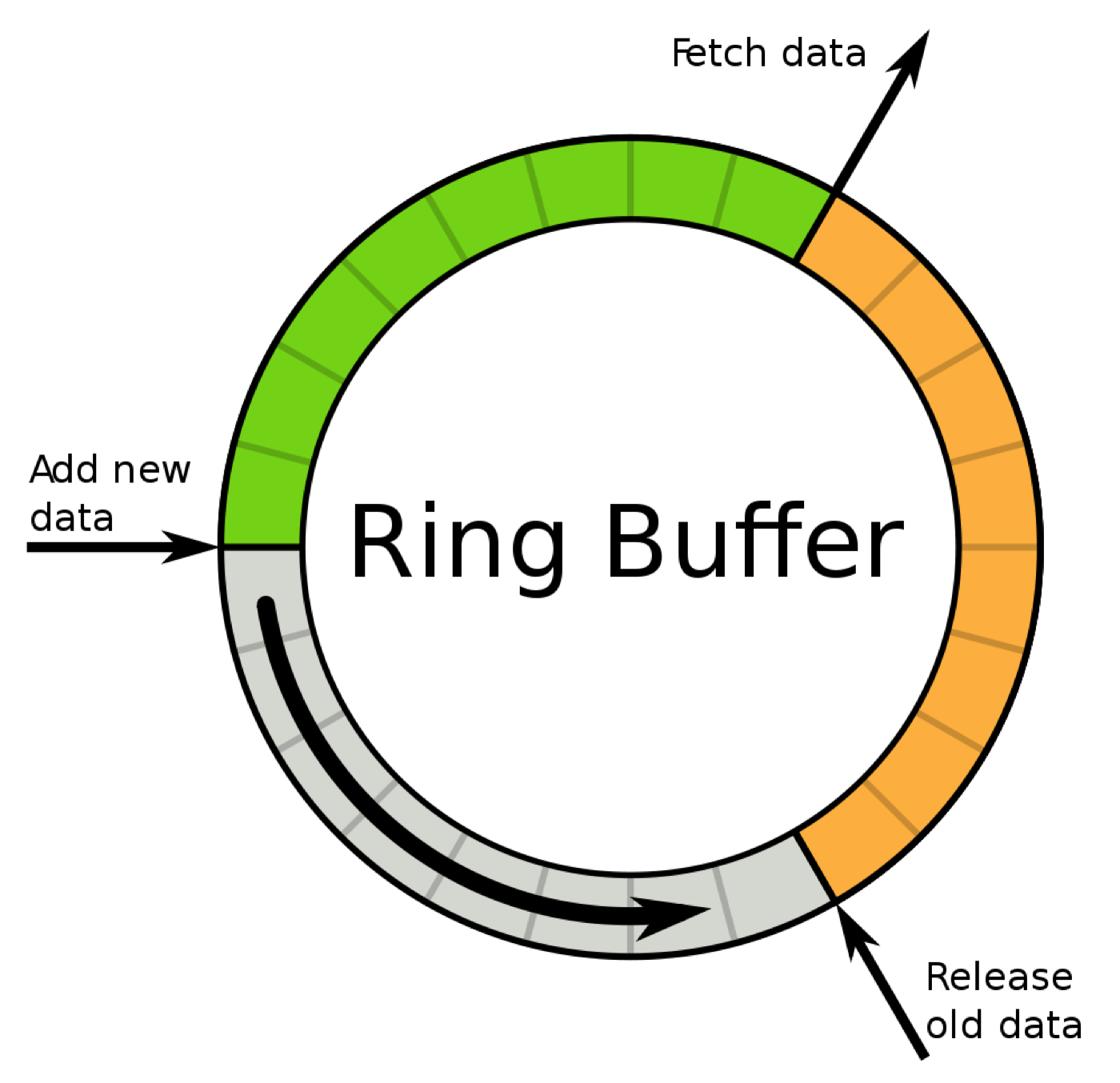
A capped collection is basically a ring buffer, meaning they are a fixed size in bytes. As we insert documents into the capped collection, they are added one after the other in the buffer, until we reach the end of the buffer. Once it gets to the end of the buffer, it wraps around and starts overwriting the documents at the start of the buffer.
The main benefit of a capped collection is that it allows for a tailing cursor, meaning applications can get notified as new documents are inserted into the collection.
The first limitation of a capped collection is that inserted documents cannot grow. If you need to change the shape of a document, you will need to insert a pre-padded document to ensure your document does not grow outside the allocated space.
The second limitation of capped collections is that they are in-memory structures only. So if the MongoDB server is shutdown, you will loose the content of the capped collection. The capped collections, will however replicate across to secondaries in a replicaset. If you need fail over support, it’s recommended to deploy a replicaset.
In this chapter we will use a stock ticker for our topic schema example.
Schema Observations
- Leverages capped collections
- Works with replication
- Performs well
- To many listeners impact CPU usage on MongoDB currently (MongoDB 3.0 or earlier).
- Collection is not persistent. If the mongodb process dies, the capped collection is gone. Use a replicaset to avoid this problem.
- Potentially read and write heavy.
Schema
| Schema attribute | Description |
|---|---|
| Optimized For | Write Performance |
| Pre-Allocation | Only if the documents need to grow |
We will use a very simplified stock ticker schema to showcase how topics can be created and used with MongoDB.
{
"time": ISODate("2014-01-01T10:01:22Z")
"ticker": "PIP",
"price": "4.45"
}
Operations
Create the capped collection
To create the capped collection, we need to use the createCollection command, passing the capped collection options.
var db = db.getSisterDB("finance");
db.createCollection("ticker", {capped:true, size:100000, max: 100000})
The available options are:
| Option | Type | Description |
|---|---|---|
| capped | boolean | Signal that we want to create a capped collection |
| autoIndexId | boolean | Create index for the _id field. Set to false when replicating the collection |
| size | number | The size of the capped collection in bytes in the collection before wrapping around |
| max | number | The maximum number of documents in the collection before wrapping around |
| usePowerOf2Sizes | boolean | Default allocation strategy from 2.6 and on |
Creating Random Ticker Documents
Let’s create some activity in our capped collection, by writing a publisher script. First boot up a new mongo shell and run a publisher that creates a new ticker document with a random price once a second.
var db = db.getSisterDB("finance");
while(true) {
db.ticker.insert({
time: new Date(),
ticker: "PIP",
price: 100 * Math.random(1000)
})
sleep(1000);
}
Ticker Consumer
To consume the messages being published to the topic, let’s write a consumer script. Boot up another mongo shell, and run a script that will consume messages from the topic.
var db = db.getSisterDB("finance");
var cursor = db.ticker.find({time: {$gte: new Date()}}).addOption(DBQuery.Option.tailable).addOption(DBQuery.Option.awaitData)
while(cursor.hasNext) {
print(JSON.stringify(cursor.next(), null, 2))
}
The script will only receive tickers that are newer than the date and time the script was started.
Indexes
The indexes for this schema will vary by how you query the data in your consumers. In this simple stock ticker publisher/consumer, we can see that we query the collection by the time field. To avoid collection scans, we create an index on the time field.
var col = db.getSisterDB("finance").ticker;
col.ensureIndex({time: 1});
Scaling
Secondary Reads
Secondary reads can help scale the number of subscribers. This allows an application to increase the number of listeners by distributing the read load across multiple secondaries.
Sharding
Capped collections do not support sharding.
Performance
Capped collections are in-memory collections and are limited to the speed of memory. Unfortunately, there is a performance limit caused by the way tailing cursors are currently implemented. As you add more and more tailing cursors, the MongoDB cpu usage increases markedly. This means that it’s important to keep the number of listeners low to get better throughput.
If you are just pulling data off the topic, and not performing any modifications to the documents using secondary reads with a replicaset might help scale the number of listeners you can deploy without creating undue cpu usage on the servers.
A simple exploration of the performance on a single machine with MongoDb 3.0 shows the difference between MMAP and WiredTiger for a narrow simulation using the schema simulation framework mongodb-schema-simulator.
Scenario
MongoDb runs locally on a MacBook Pro Retina 2015 with ssd and 16 gb ram. The simulation runs with the following parameters against a single mongod instance under osx 10.10 Yosemite.
| Parameters | Value |
|---|---|
| processes | 4 |
| poolSize per process | 50 |
| type | linear |
| Resolution in milliseconds | 1000 |
| Iterations run | 25 |
| Total number of users publishing per iteration | 1000 |
| Total number of users reading per iteration | 40 |
| Execution strategy | slicetime, custom |
MMAP
The MMAP engine is run using the default settings on MongoDB 3.0.1.

publish_to_topics scenario results
| Statistics | Value |
|---|---|
| Runtime | 44.39 seconds |
| Mean | 2.616 milliseconds |
| Standard Deviation | 7.824 milliseconds |
| 75 percentile | 2.318 milliseconds |
| 95 percentile | 5.523 milliseconds |
| 99 percentile | 21.792 milliseconds |
| Minimum | 0.703 milliseconds |
| Maximum | 420.747 milliseconds |
fetch_from_topics scenario results
| Statistics | Value |
|---|---|
| Runtime | 44.39 seconds |
| Mean | 0.001 milliseconds |
| Standard Deviation | 0.003 milliseconds |
| 75 percentile | 0.002 milliseconds |
| 95 percentile | 0.004 milliseconds |
| 99 percentile | 0.02 milliseconds |
| Minimum | ~0.00 milliseconds |
| Maximum | 0.323 milliseconds |
There doesn’t seem to much to note here. The writes per second is pretty much exactly 1000, mirroring the number of concurrent users we have defined in the simulation. As the capped collection is in-memory, the writing speed is limited only to MongoDB’s lock handling and memory performance.
One thing to keep in mind, is that before MongoDB 3.0 the MMAP engine only supported db level locking which meant it was better to place a high throughput capped collection in its own separate database. In MongoDB 3.0 the MMAP engine lowers the lock level to collection level which means it can coexist with other collections in the same database without impacting other collections with lock contention.
WiredTiger
The WiredTiger engine is run using the default settings on MongoDB 3.0.1.

publish_to_topics scenario results
| Statistics | Value |
|---|---|
| Runtime | 45.39 seconds |
| Mean | 2.848 milliseconds |
| Standard Deviation | 11.15 milliseconds |
| 75 percentile | 2.432 milliseconds |
| 95 percentile | 5.699 milliseconds |
| 99 percentile | 22.597 milliseconds |
| Minimum | 0.740 milliseconds |
| Maximum | 522.21 milliseconds |
fetch_from_topics scenario results
| Statistics | Value |
|---|---|
| Runtime | 45.39 seconds |
| Mean | 0.001 milliseconds |
| Standard Deviation | 0.004 milliseconds |
| 75 percentile | 0.002 milliseconds |
| 95 percentile | 0.004 milliseconds |
| 99 percentile | 0.020 milliseconds |
| Minimum | ~0.00 milliseconds |
| Maximum | 0.363 milliseconds |
WiredTiger does not really make a big difference here compared to MMAP as the back end storage system is memory and not disk. Remember that WiredTiger supports document level locking. So there is no need to take into consideration placing the capped collection in its own separate db to avoid lock contention, as for MMAP pre MongoDB 3.0.
Notes
Capped collection can be extremely useful to create topic like systems, where you have multiple publishers and subscribers. However due to the current limitations on how tailed cursors work in MongoDB currently, it’s important to balance the number of active listeners with the cpu usage.