- Schema Book
- Queue
Queue
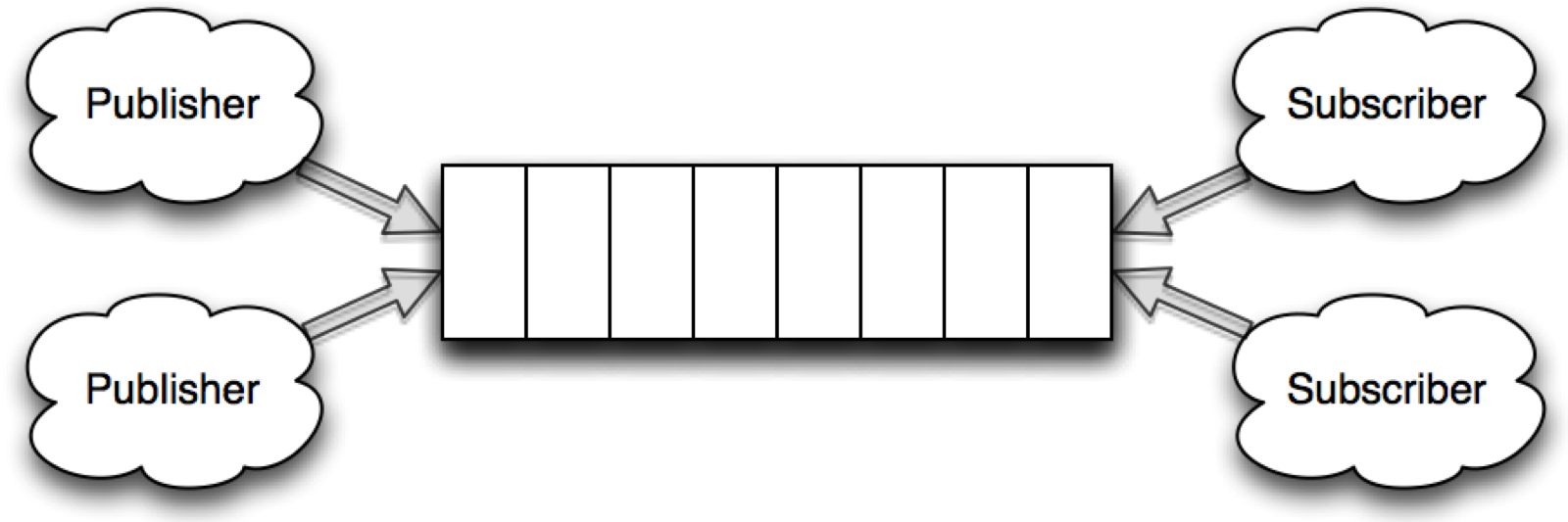
A queue in the setting of MongoDB, means a collection where inserted documents are kept in an order, either by the creation data of the document or by a priority assigned to the document. Multiple publishers can be inserting new documents into the queue at the same time, but each document can only be delivered to a single listener.
The queue schema introduced in this chapter is a work queue that is used to enqueue work for a set of listening processes. A job is represented by a document and can be dequeued either in FIFO (first in first out) order or by priority.
Schema Observations
- Efficient retrieval of queue jobs.
- Flexible.
- Easily adaptable to increased performance using an index.
- Relies on findAndModify, which means it’s imperative that the query aspect of the operation is as efficient as possible in order to minimize write locks (less of an issue with WiredTiger).
- Potentially read and write intensive.
Schema
| Schema attribute | Description |
|---|---|
| Optimized For | Write/Read Performance |
The schema expressed here only contains the minimal set of fields needed to represent work items. One of the things omitted, is the ability to identify what process is working on a specific item. There is also no additional meta data provided about the work item itself.
{
'startTime': date
, 'endTime': date
, 'createdOn': date
, 'priority': number
, 'payload': object
}
For this schema we will use the following fields.
| Field | Description |
|---|---|
| startTime | The time the job was started |
| endTime | The time the job ended |
| createdOn | The time the document was created |
| priority | A numeric priority where a higher value is higher priority |
| payload | An embedded document that is the work payload |
One could easily extend the schema by adding a process_id field that could contain the information about what listener picked up the document.
Operations
Let’s look at the different operations we can perform on the queue schema.
Inserting a Job
Inserting a job into the work queue is fairly simple and straight forward using the shell as an example.
var col = db.getSisterDB("work").queue;
col.insert({
'startTime': null
, 'endTime': null
, 'createdOn': new Date()
, 'priority': 1
, 'payload': {
'type': 'convertImage'
, 'source': '/images/image.png'
, 'output': '/images/image.jpg'
}
});
In this example, we insert a new job that converts images from one type to another.
Return the next FIFO Job
If we wish to fetch the next item using FIFO, we can do this in the following way.
var col = db.getSisterDB("work").queue;
var job = col.findAndModify({
query: {startTime: null}
, sort: {createdOn: 1}
, update: {$set: {startTime: new Date()}}
, new: true
});
This query will retrieve the document with the oldest createdOn data, and set the startTime field to the current Date, before returning the updated document.
important
findAndModify
One thing to remember is that findAndModify takes a write lock for the duration of the operation. What this means in practice, is that it will not allow concurrent writes to happen while the operation is in process. The impact of this lock depends on the version of MongoDB.
MongoDB 2.6 and earlier have a db level lock that will block the database for write operations. MongoDB 3.0 improves on this for the MMAP engine by making it a collection level lock. If you use the WiredTiger storage engine it only requires a document level lock.
It’s important to ensure there is an index on createdOn to reduce the total time the findAndModify operation takes to execute.
Return the Highest Priority Job
To fetch a job sorted by the highest priority and created date, we perform a slightly different query to the FIFO one.
var col = db.getSisterDB("work").queue;
var job = col.findAndModify({
query: {startTime: null}
, sort: {priority: -1, createdOn: 1}
, update: {$set: {startTime: new Date()}}
, new: true
});
This query differs from the FIFO one in a particular way. First, we sort by priority and then perform a secondary sorting on createdOn.
Finishing a Job
When we have finished processing a job we simply update the job endTime, signaling that the job was done.
var col = db.getSisterDB("work").queue;
col.update({_id: job._id}, {$set: {endTime: new Date()}});
We look up the job by using the job._id field and set the endTime field to the current data and time.
Indexes
There are a couple of indexes that we can create to help performance with this schema. Let’s look at what kind of queries we are performing for the queue schema.
Return the next FIFO Job
The query is {startTime: null} and we sort by {createdOn:1}. To effectively use an index, we can create a composite index featuring the two fields. This allows both the query and sort to each use an index.
var col = db.getSisterDB("work").queue;
col.ensureIndex({startTime: 1, createdOn: 1});
When executing the query part of the findAndModify with the explain command:
var col = db.getSisterDB("work").queue;
col.find({startTime: null}).sort({createdOn: 1}).explain()
The result field cursor contains the text BtreeCursor showing that the query has executed using an index. In our case the cursor field looked like this.
"cursor" : "BtreeCursor startTime_1_createdOn_1"
This is the expected outcome, as we wish to avoid performing a collection level scan. Here, the worst case scenario is an index scan for all entries where startTime is null.
Return the highest Priority Job
The query is slightly different from the FIFO one, as we involve three different fields. The query is {startTime: null} is the same as the FIFO query, but the sort includes both the priority and createdOn fields {priority: -1, createdOn: 1}. This particular query benefits from a compound index containing all three fields. Let’s create the index using ensureIndex.
var col = db.getSisterDB("work").queue;
col.ensureIndex({startTime: 1, priority: -1, createdOn: 1});
Execute the query part of the findAndModify with explain
var col = db.getSisterDB("work").queue;
col.find({startTime: null}).sort({priority: -1, createdOn: 1}).explain()
Just as with the FIFO query, we see that the cursor field returned contains the word BtreeCursor. In our case it comes back looking like this.
"cursor" : "BtreeCursor startTime_1_priority_-1_createdOn_1"
This is the expected outcome as we wish to avoid performing a collection level scan. Here, the worst case scenario is an index scan for all entries where startTime is null.
TTL Indexes
MongoDB 2.4 or higher has a new type of index called TTL, that lets the server remove documents gradually over time. Let’s look at an example document.
{
'startTime': ISODate("2014-01-01T10:02:22Z")
, 'endTime': ISODate("2014-01-01T10:06:22Z")
, 'createdOn': ISODate("2014-01-01T10:01:22Z")
, 'priority': 1
, 'payload': {
'type': 'convertImage'
, 'source': '/images/image.png'
, 'output': '/images/image.jpg'
}
}
We want to only keep the last 24 hours worth of jobs once they are finished. Before MongoDB 2.4 the only way to accomplish this would be to perform a batch remove using a script or application.
With the introduction of the TTL index, we can let MongoDB perform the deletion of documents for us avoiding additional code and the possible interruptions to write performance bulk deletes might cause. Creating the TTL index is very straightforward.
var db = db.getSisterDB("data");
var numberOfSeconds = 60 * 60 * 24; // 60 sec * 60 min * 24 hours
db.expire.ensureIndex({ "endTime": 1}, {expireAfterSeconds: numberOfSeconds })
This creates a TTL index on the endTime field that will remove any documents where the endTime field is older than 24 hours.
important
Time To Live Indexes (TTL)
The TTL index is not a hard real-time limit. It only guarantees that documents will be expired some time after they hit the expire threshold, but this period will vary depending on the load on MongoDB and other currently running operations.
Scaling
Secondary Reads
All the operations against the queue are write operations so secondary reads are not useful for this schema.
Sharding
Both the FIFO and priority based queues use findAndModify querying on startTime equal to null. If we used startTime as the shard key the findAndModify will fail as it attempts to set the startTime field which is immutable as it’s the shard key. There is no real way around this so sharding does not make sense for this particular schema.
If you wish to scale the schema, you can do this by creating multiple collections and assigning the collections to separate shards thus spreading the writes across multiple MongoDb servers.
Performance
Performance is limited to the amount of time it takes for the findAndModify to finish. With the MMAP storage engine the lock level is db level in 2.6 and collection level in 3.0. For WiredTiger the document level locking means that performance is less impacted by findAndModify.
A simple exploration of the performance on a single machine with MongoDb 3.0 shows the difference between MMAP and WiredTiger for a narrow simulation using the schema simulation framework mongodb-schema-simulator.
Scenario
MongoDb runs locally on a MacBook Pro Retina 2015 with ssd and 16 gb ram. The simulation runs with the following parameters against a single mongodb instance under osx 10.10 Yosemite.
| Parameters | Value |
|---|---|
| processes | 4 |
| poolSize per process | 50 |
| type | linear |
| Resolution in milliseconds | 1000 |
| Iterations run | 25 |
| Total number of users publishing per iteration | 1000 |
| Total number of users reading per iteration | 300 |
| Execution strategy | slicetime |
Warning
warning
This is not a performance benchmark
The graphs here are shown to give an understanding of the difference between the two storage engines available and IS NOT indicative of the performance obtained on a real production system. Furthermore more it’s important to understand that MongoDB is not optimized for osx.
The mongodb-schema-simulator tool was made expressively so you can simulate these schemas yourself on your own hardware.
MMAP
The MMAP engine is run using the default settings on MongoDB 3.0.1.
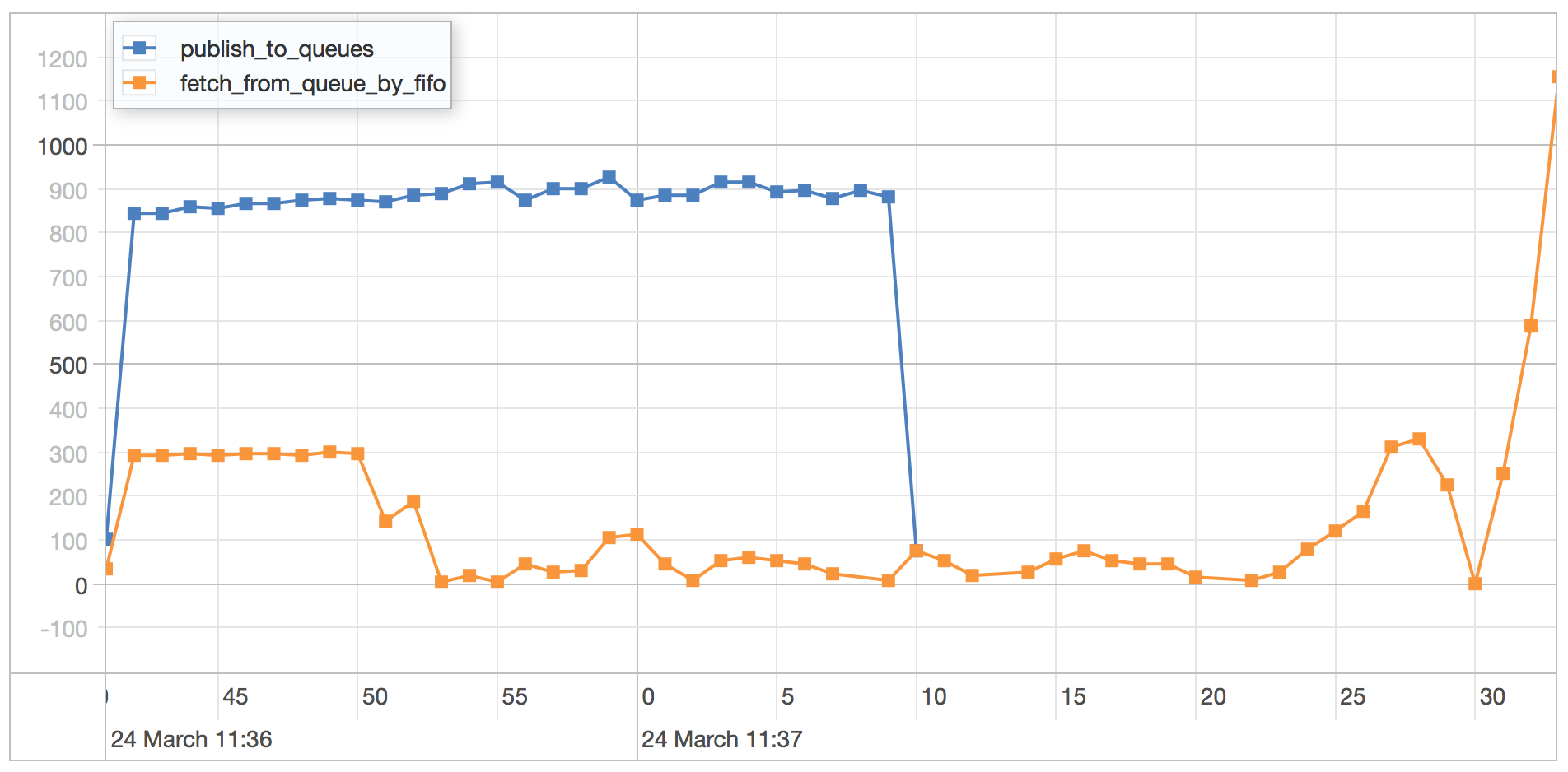
publish_to_queues scenario results
| Statistics | Value |
|---|---|
| Runtime | 52.289 seconds |
| Mean | 31.288 milliseconds |
| Standard Deviation | 21.479 milliseconds |
| 75 percentile | 48.616 milliseconds |
| 95 percentile | 55.736 milliseconds |
| 99 percentile | 59.138 milliseconds |
| Minimum | 0.401 milliseconds |
| Maximum | 77.987 milliseconds |
fetch_from_queue_by_fifo scenario results
| Statistics | Value |
|---|---|
| Runtime | 52.289 seconds |
| Mean | 15195.361 milliseconds |
| Standard Deviation | 13526.237 milliseconds |
| 75 percentile | 28049.003 milliseconds |
| 95 percentile | 33552.295 milliseconds |
| 99 percentile | 35403.374 milliseconds |
| Minimum | 1.233 milliseconds |
| Maximum | 37248.023 milliseconds |
What we can observe here is the cost of the collection level write lock in MMAP as all the writes get priority over the reads swamping the server and limiting read throughput. As the writes tail off, the queued reads start getting through but due to the large backlog the average time of the reads increases dramatically in comparison to the writes.
WiredTiger
The WiredTiger engine is run using the default settings on MongoDB 3.0.1.
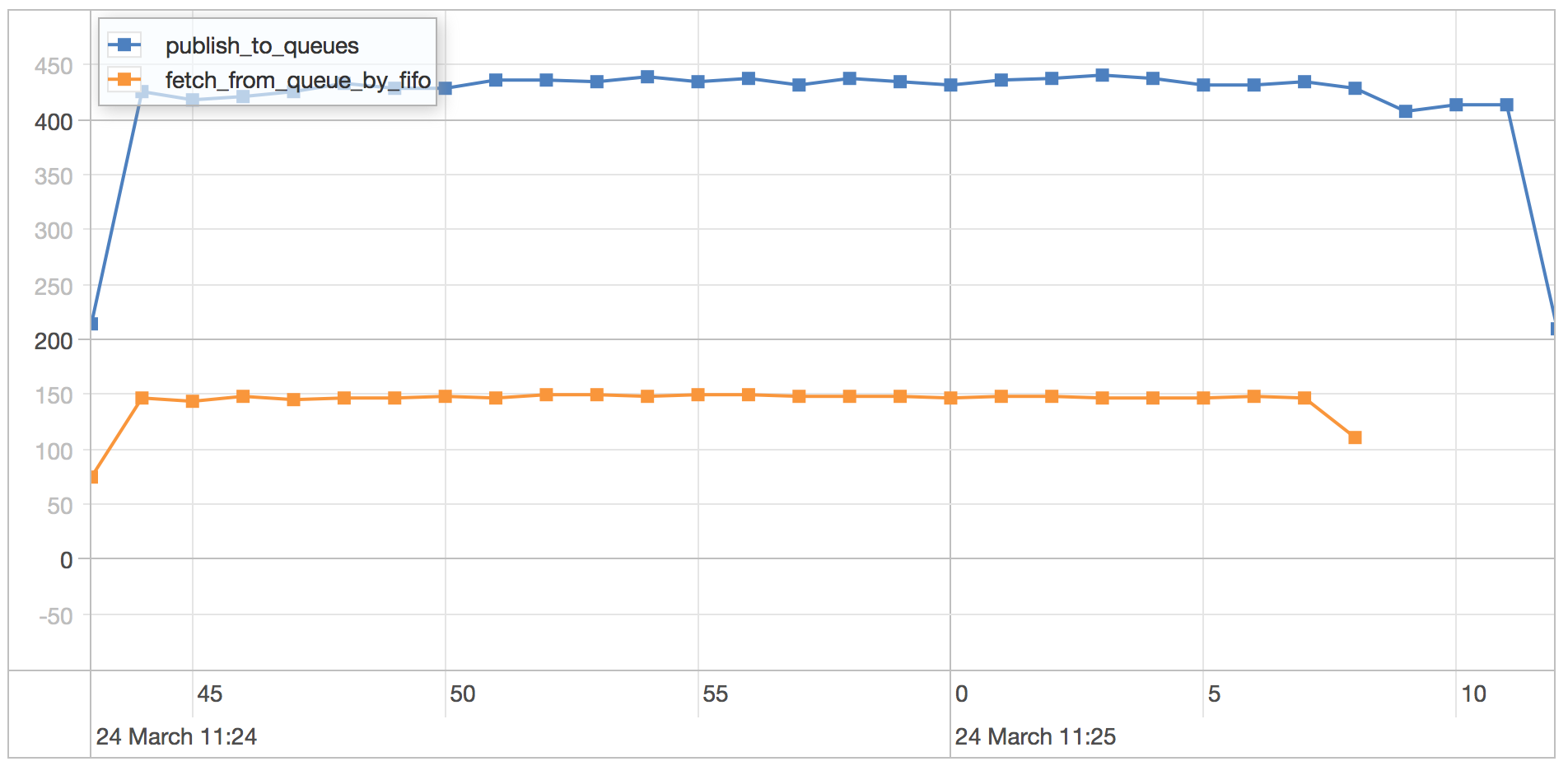
publish_to_queues scenario results
| Statistics | Value |
|---|---|
| Runtime | 31.113 seconds |
| Mean | 32.455 milliseconds |
| Standard Deviation | 44.732 milliseconds |
| 75 percentile | 51.322 milliseconds |
| 95 percentile | 127.275 milliseconds |
| 99 percentile | 188.452 milliseconds |
| Minimum | 0.412 milliseconds |
| Maximum | 312.698 milliseconds |
fetch_from_queue_by_fifo scenario results
| Statistics | Value |
|---|---|
| Runtime | 31.113 seconds |
| Mean | 48.493 milliseconds |
| Standard Deviation | 718.43 milliseconds |
| 75 percentile | 5.873 milliseconds |
| 95 percentile | 10.658 milliseconds |
| 99 percentile | 29.38 milliseconds |
| Minimum | 1.329 milliseconds |
| Maximum | 19499.33 milliseconds |
We can see the benefit of document level locking here as the writes are spread out more evenly across the whole runtime when WiredTiger yields to reads. However, the improvement is not huge and it comes with a much bigger cpu overhead. WiredTiger does not support inplace updates and has to copy the data for each findAndModify that is performed.
Notes
Picking the right storage engine for the schema is imperative. Although WiredTiger is somewhat faster in this scenario it’s important to consider its higher cpu usage and the fact that it does not support in place updates which could impact performance depending on the size of the document.