- Schema Book
- Array Slice Cache
Array Slice Cache
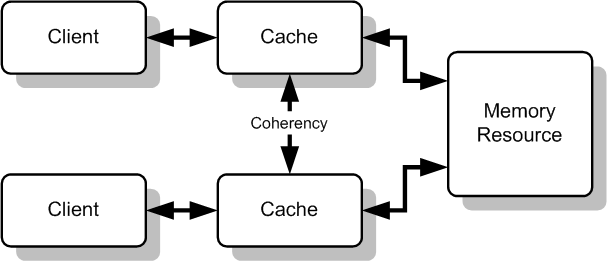
The array slice cache is a document level cache that leverages the $slice operator in an update statement and allows us to operate on embedded arrays in documents. The operator lets us ensure that an embedded array only has a maximum of n entries in it.
A positive sliceAt will slice from the front and a negative will slice from the end. The first example has a negative sliceAt value. It takes:
var array = [ 40, 50, 60 ]
var sliceAt = -5
var items = [ 80, 78, 86 ]
var result = [ 50, 60, 80, 78, 86 ]
The second example has a positive sliceAt value. It pushes two values to the end of the array and slices it at 3 elements.
var array = [ 89, 90 ]
var sliceAt = 3
var items = [ 100, 20 ]
var result = [ 89, 90, 100 ]
The schema we will showcase here is a blog post document that contains the 10 latest comments inside an embedded array. This embedded array acts as a cache to avoid additional queries against the comments collection when retrieving the main blog web view.
Schema Observations
- Allows for keeping a cache inside the document itself.
- Lets the application optimize for single document reads.
- Requires additional logic in your application to keep the cache current.
Schema
In our case, we’re are going to use a very simple blog post schema to show how the cache would work.
Let’s look at a post document from the posts collection with a single comment.
{
"_id": ObjectId("54fd7392742abeef6186a68e")
, "blogId": ObjectId("54fd7392742abeef6186a68e")
, "createdOn": ISODate("2015-03-11T12:03:42.615Z")
, "publishedOn": ISODate("2015-03-11T12:03:42.615Z")
, "title": "Awesome blog post"
, "content": "Testing this blog software"
, "latestComments": [{
"_id": ObjectId("54fd7392742abeef6186a68e")
, "publishedOn": ISODate("2015-03-11T12:03:42.615Z")
, "message": "Awesome post"
}]
}
A simple comment document from the comments collection.
{
"_id": ObjectId("54fd7392742abeef6186a68e")
, "postId": ObjectId("54fd7392742abeef6186a68e")
, "publishedOn": ISODate("2015-03-11T12:03:42.615Z")
, "message": "Awesome post"
}
Operations
Add a comment
When a user enters a comment, it first gets written into the comments collection and then added to the latestComments embedded array cache in the blog post document. For this example, we are going assume, that we have a blog post in the posts collection with the field _id set to the value 1.
var postId = 1;
var posts = db.getSisterDB("blog").posts;
var comments = db.getSisterDB("blog").comments;
var comment = {
"_id": ObjectId("54fd7392742abeef6186a68e")
, "postId": postId
, "publishedOn": ISODate("2015-03-11T12:03:42.615Z")
, "message": "Awesome post"
};
comments.insert(comment);
posts.update({
"_id": postId
}, {
latestComments: {
$each: [comment]
, $slice: -10
}
});
This will add the new comment to the end of the latestComments embedded array and slice it from the start at 10 elements. To display the ten latest comments in descending order, all we would need to do is read the blog post document and reverse the latestComments array to get the comments in the right order.
Indexes
We do not need any specific indexes in this example as we are always referencing documents by the _id field.
Scaling
Secondary Reads
The secondary reads will come with a latency penalty given that any changes to the cache might take some time to replicate across to the secondaries. However, depending on the applications’ needs, this latency might be acceptable. An example might be a Content Management System (CMS) where publishing an article might not need to be immediately available across the entire web site.
Here, secondary reads would allow us to offload reads from the primary, and distribute the load across multiple secondaries.
Sharding
For sharding it makes sense to select a shard key that places all blog posts on the same shard. For the comments you also want all the comment queries to be routed to the same shard for a specific blog post.
To do this efficiently, we should use a compound shard key that will contain a routing part (the blogId) as well as a rough time stamp (ObjectId). In our case, the logical key is {blogId: 1, _id: 1} for the posts collection.
var admin = db.getSisterDB("admin");
db.runCommand({enableSharding:'blogs'});
db.runCommand({
shardCollection: 'blogs.posts'
, key: {blogId:1, _id:1}
});
posts collection
Similarly for the comments collection we should group the comments together on the same shard so we can create a compound shard key {postId:1, _id:1} routing by postId.
var admin = db.getSisterDB("admin");
db.runCommand({enableSharding:'blogs'});
db.runCommand({
shardCollection: 'blogs.comments'
, key: {postId:1, _id:1}
});
comments collection
Performance
Performance is good here as the $slice update operator ensures we do mostly in place updates. In the case of the blog example, we might get more document moves as the size of latestComments might change due to different comment sizes. In cases where we use uniform sized documents, we will not incur any additional document moves.
tip
Preallocate
If we have uniform sized documents to be inserted into the document level line cache we can avoid document moves by pre-allocating the embedded document by filling it with empty documents of the expected size, meaning the document will not be moved around once we start pushing documents into the cache.
A simple exploration of the performance on a single machine with MongoDb 3.0 shows the difference between MMAP and WiredTiger for a narrow simulation using the schema simulation framework mongodb-schema-simulator.
Scenarios
MongoDb runs locally on a MacBook Pro Retina 2015 with ssd and 16 gb ram. The simulation runs with the following parameters against a single mongodb instance under osx 10.10 Yosemite.
Pre-allocated slice cache
| Parameters | Value |
|---|---|
| processes | 4 |
| poolSize per process | 50 |
| type | linear |
| Resolution in milliseconds | 1000 |
| Iterations run | 25 |
| Number of users | 1000 |
| Execution strategy | slicetime |
Slice cache no pre-allocation
| Parameters | Value |
|---|---|
| processes | 4 |
| poolSize per process | 50 |
| type | linear |
| Resolution in milliseconds | 1000 |
| Iterations run | 25 |
| Number of users | 1000 |
| Execution strategy | slicetime |
MMAP
The MMAP engine is run using the default settings on MongoDB 3.0.1.
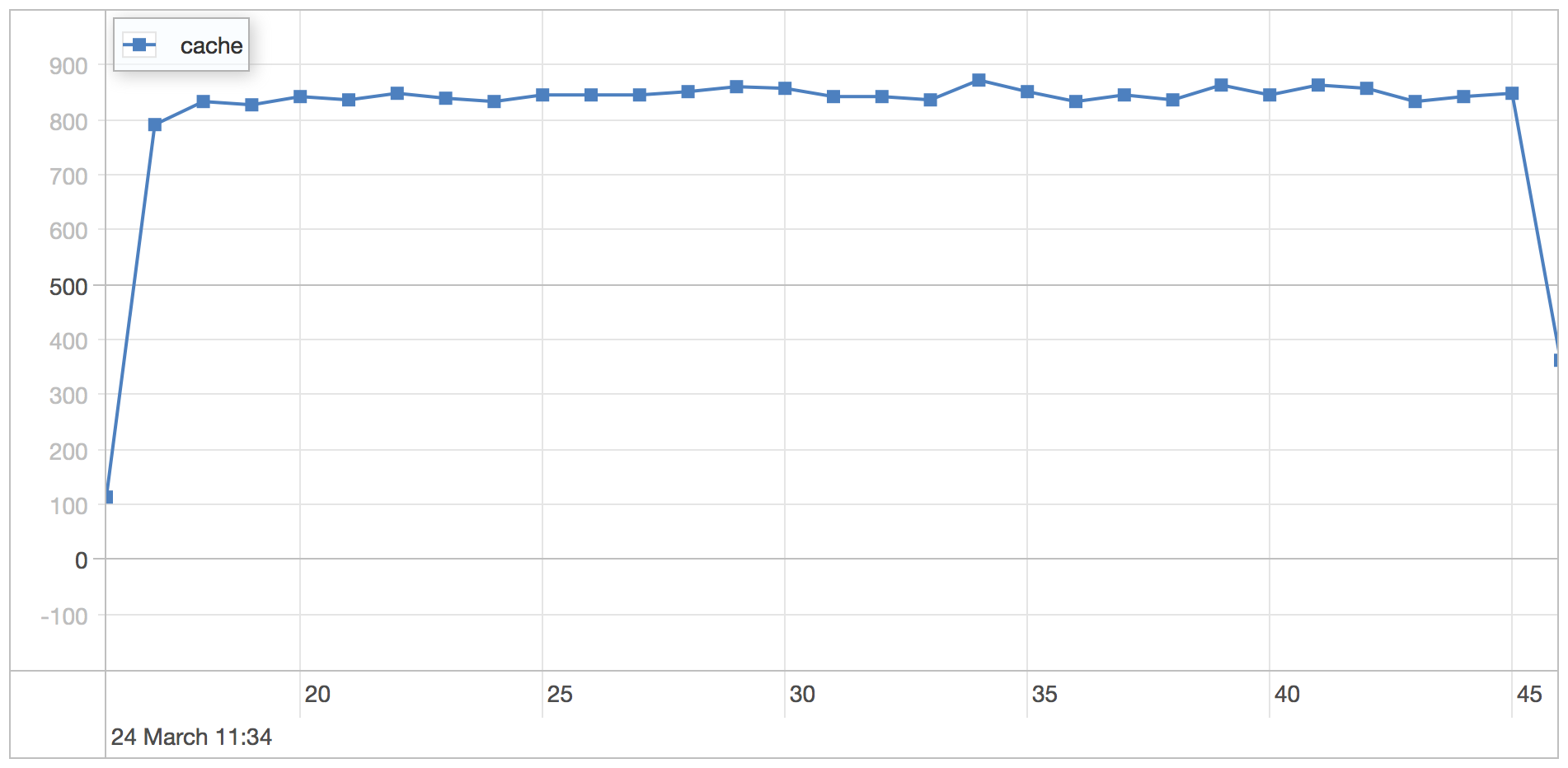
Pre-allocated slice cache
| Statistics | Value |
|---|---|
| Runtime | 30.98 seconds |
| Mean | 0.668 milliseconds |
| Standard Deviation | 0.163 milliseconds |
| 75 percentile | 0.715 milliseconds |
| 95 percentile | 0.874 milliseconds |
| 99 percentile | 1.155 milliseconds |
| Minimum | 0.361 milliseconds |
| Maximum | 5.799 milliseconds |
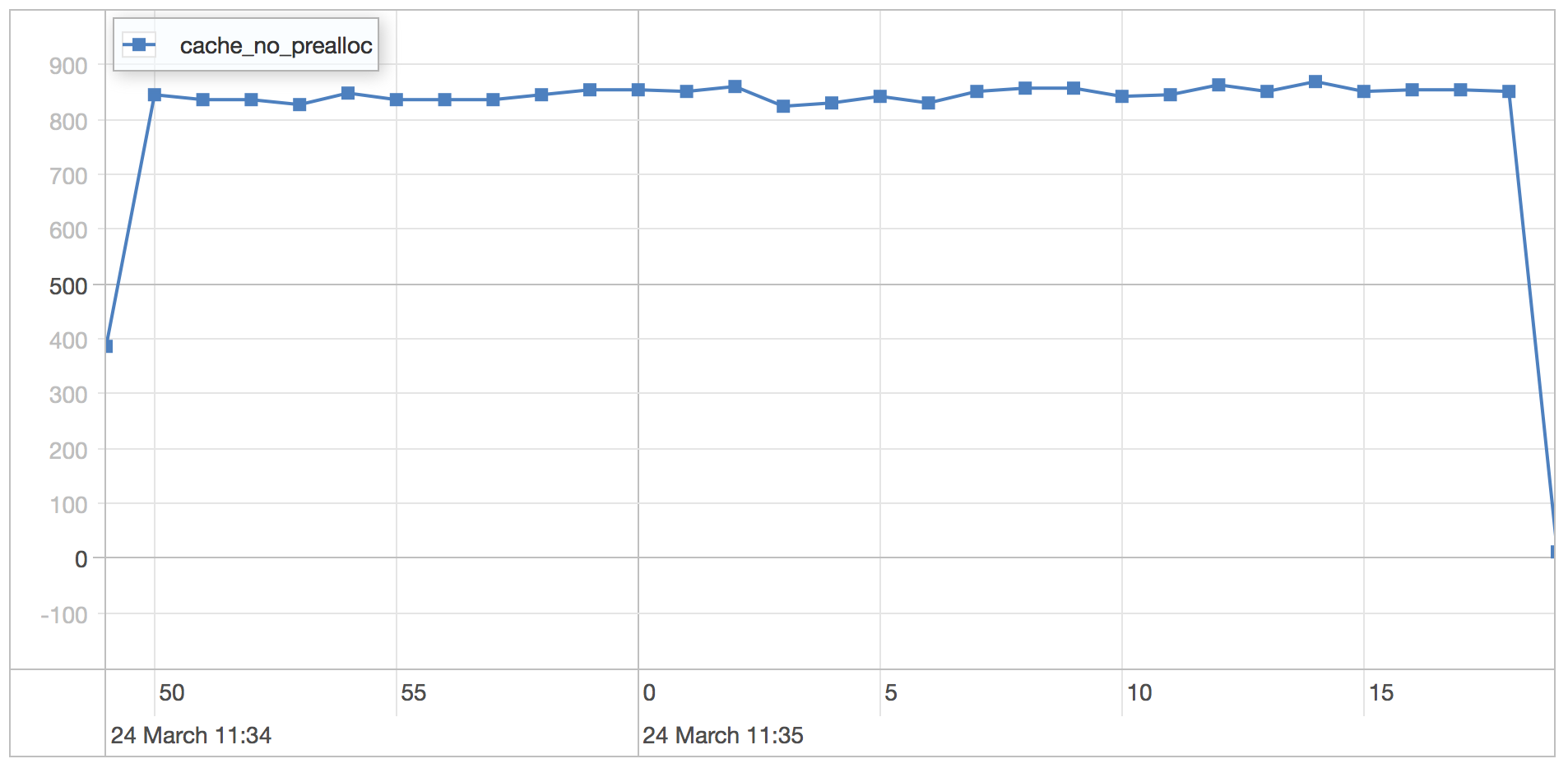
Slice cache no pre-allocation
| Statistics | Value |
|---|---|
| Runtime | 30.507 seconds |
| Mean | 0.663 milliseconds |
| Standard Deviation | 0.155 milliseconds |
| 75 percentile | 0.715 milliseconds |
| 95 percentile | 0.86 milliseconds |
| 99 percentile | 1.088 milliseconds |
| Minimum | 0.365 milliseconds |
| Maximum | 8.494 milliseconds |
WiredTiger
The WiredTiger engine is run using the default settings on MongoDB 3.0.1.
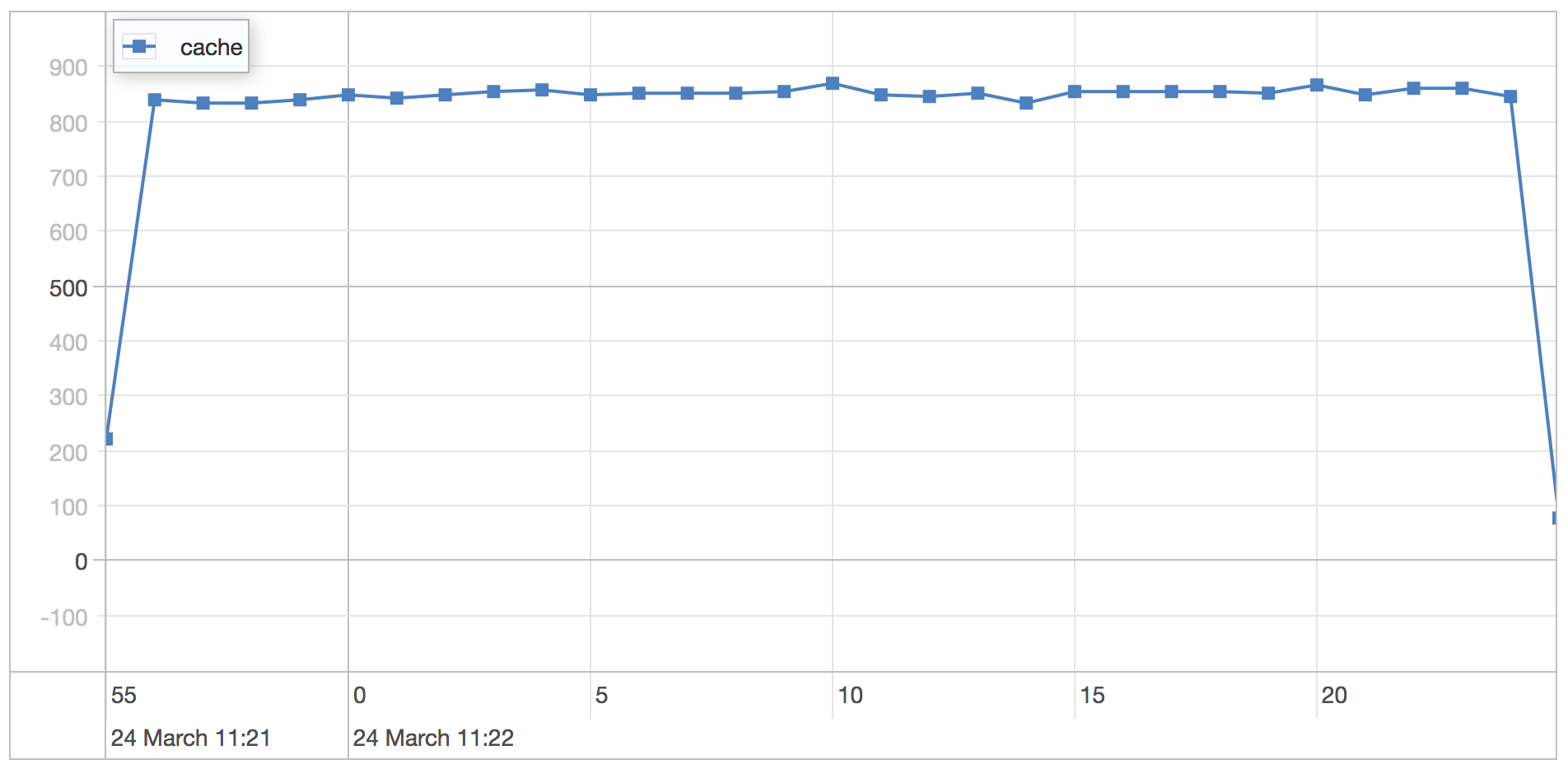
Pre-allocated slice cache
| Statistics | Value |
|---|---|
| Runtime | 30.606 seconds |
| Mean | 0.756 milliseconds |
| Standard Deviation | 0.199 milliseconds |
| 75 percentile | 0.812 milliseconds |
| 95 percentile | 1.085 milliseconds |
| 99 percentile | 1.418 milliseconds |
| Minimum | 0.408 milliseconds |
| Maximum | 5.627 milliseconds |
Slice cache no pre-allocation
| Statistics | Value |
|---|---|
| Runtime | 30.033 seconds |
| Mean | 1.012 milliseconds |
| Standard Deviation | 0.4 milliseconds |
| 75 percentile | 1.234 milliseconds |
| 95 percentile | 1.783 milliseconds |
| 99 percentile | 2.185 milliseconds |
| Minimum | 0.417 milliseconds |
| Maximum | 8.582 milliseconds |
The variance between MMAP and WiredTiger is minor in both cases. The small difference between pre-allocation and no pre-allocation is mostly due to the fact that we have a uniform object size in this test. If the cache document size is fairly big, it will impact WiredTiger since it needs to rewrite more data on each update.
Notes
This is an effective way cache results in the main document without incurring the side effects of unbound growing embedded documents. It’s a strategy that is useful when you wish to optimize for single document reads for specific web or application views. In this specific example, we can imagine a web page view showing a blog post with its ten latest comments.