- Schema Book
- Materialized Path Category Hierarchy
Materialized Path Category Hierarchy
The nested categories schema design pattern targets the hierarchical tree structures traditionally found in a product catalog on an e-commerce website.
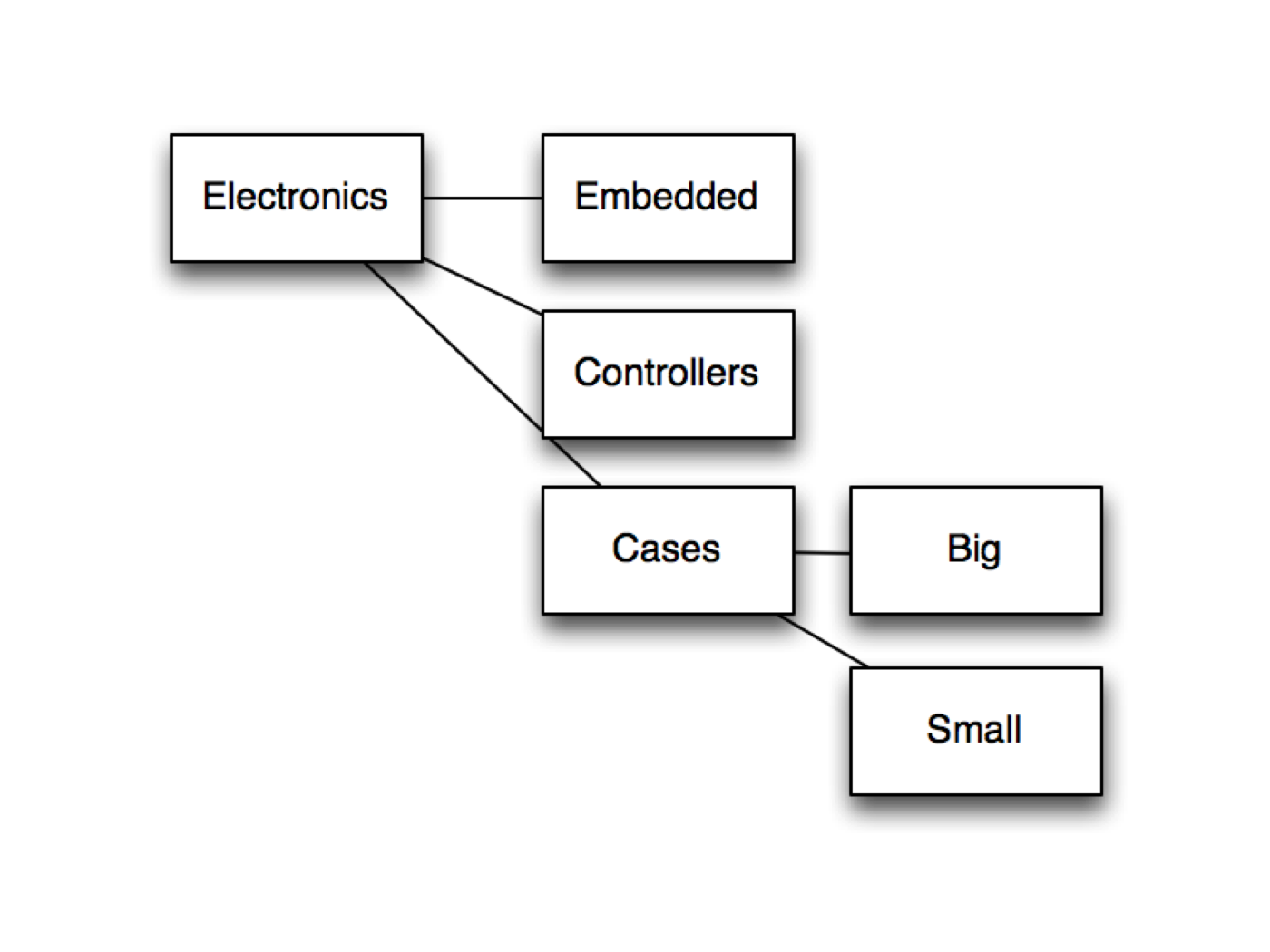
We’ll will be presenting a pattern called the materialized path pattern. This pattern refers to categories by a file system like path concept /monitors/lg/led.
Schema Observations
- Allows for efficient retrieval of a category’s direct children or subtree.
- Very flexible.
- Makes it easy to allow products to belong to multiple categories.
- Easily adaptable to increased performance using an index.
- Relies on regular expressions, making it more complicated (a wrong regular expression can easily cause a full collection scan)
Schema
Lets look at an example category document.
{
"_id": ObjectId("54fd7392742abeef6186a68e")
, "name": "embedded"
, "parent": "/electronics"
, "category": "/electronics/embedded"
}
Schema
| Schema Attribute | Description |
|---|---|
| name | Name of the category |
| parent | The parent category path. If the parent is the root it will be / |
| category | The current category path |
Lets insert a stripped down product document.
{
"_id": ObjectId("54fd7392742abeef6186a68e")
, "name": "Arduino"
, "cost": 125
, "currency": "USD"
, "categories": ["/electronics/embedded"]
}
| Schema attribute | Description |
|---|---|
| name | Name of the product |
| cost | The cost of the product |
| currency | The product currency |
| categories | An embedded array of category paths for this product. A product can belong to one or more categories |
Operations
Find the direct ancestors of a specified category
We want to retrieve all the direct children categories of the /electronics category.
var col = db.getSisterDB("catalog").categories;
var categories = col.find({parent: /^\/electronics$/});
/electronics category
Notice the regular expression /^\/electronics$/ that we’re using. This translates as all documents, where the field parent starts with /electronics and ends with /electronics.
Find the subtree of a specific category
We want to retrieve the entire subtree of categories for the /electronics category.
var col = db.getSisterDB("catalog").categories;
var categories = col.find({parent: /^\/electronics/});
/electronics category
Notice the regular expression /^\/electronics/ that we’re using. This regular expression matches all documents where the field parent starts with /^\/electronics/. The effect is such that the query will return all the categories in the subtree below /electronics.
Find all products by category
It’s fairly straightforward to query for products by a specific category, thanks to the embedded categories field.
var col = db.getSisterDB("catalog").products;
var products = col.find({categories: "/electronics/arduino"});
/electronics/arduino category
Find all the categories in the parent path for a specific category
To get all the categories in the parent path for a specific category, we need to do some preprocessing of the path for the specific category.
var elements = '/electronics/embedded/arduino'.split('/');
var paths = [];
for(var i = 0; i < elements.length - 1; i++) {
elements.pop();
paths.push(elements.join('/'));
}
paths.push('/');
paths.reverse();
var col = db.getSisterDB("catalog").categories;
var products = col.find({ name: { $in: paths } });
/electronics/embedded/arduino
In the example above, we created all the combinations of paths possible from the originating path /electronics/embedded/arduino by creating an array containing all the paths from the route the parent category of our provided path. In this case that becomes the array [ '/', '/electronics', '/electronics/embedded' ].
Find all the products for a category’s direct children
If we wish to find all the products for a specific category’s direct children, we have to first retrieve the category and then perform an $in query on the products collection.
var c = db.getSisterDB("catalog").categories;
var p = db.getSisterDB("catalog").products;
var categories = c.find({parent: /^\/electronics$/}).map(function(x) {
return x.category;
});
var products = p.find({ categories: { $in: categories } });
Find all the products in a category subtree
In order to locate all the products for a specific category’s subtree, we need to first retrieve the category and then perform an $in query on the products collection.
var c = db.getSisterDB("catalog").categories;
var p = db.getSisterDB("catalog").products;
var categories = c.find({parent: /^\/electronics/}).map(function(x) {
return x.category;
});
var products = p.find({ categories: { $in: categories } });
Indexes
We retrieve categories by the parent and category fields. Let’s ensure we can index on the category field as well as the parent field for the categories collection.
var col = db.getSisterDB("catalog").categories;
col.ensureIndex({category:1});
category field index
We also need to create an index for the parent field.
var col = db.getSisterDB("catalog").categories;
col.ensureIndex({parent:1});
parent field index
For the products collection we retrieve products by using the categories field. So, let’s ensure we have an index for the categories field.
var col = db.getSisterDB("catalog").products;
col.ensureIndex({categories:1});
categories field index
Covered Index Queries
Covered index queries are queries that can be answered using only the information stored in the index. Basically MongoDB answers the query using the fields stored in an index but never actually materializes the document into memory. We could create a covered index for categories to allow for quick retrieval of a specific category path.
var col = db.getSisterDB("catalog").categories;
col.ensureIndex({parent:1, name: 1})
The Index {parent:1, name:1} is a compound index and will contain both the parent and name fields, and can cover queries containing both those fields.
Let’s rewrite the query of all the categories just below the top level /electronics and look at the explain plan.
var col = db.getSisterDB("catalog").categories;
col.find({parent: /^\/electronics$/}, {_id:0, parent:1, name:1}).explain();
This should return a document result that contains a field indexOnly that is set to true indicating that the query can be answered by only using the index. You will have to give up the _id field for this query. In many cases covered index queries can provide a significant performance boost over normal queries as it avoids accessing the documents during the read operation.
Knowing this we can rewrite the query for the direct sub categories of the path /electronics.
var col = db.getSisterDB("catalog").categories;
var categories = col.find({parent: /^\/electronics/}, {_id:0, parent:1, name:1});
Scaling
Secondary Reads
In the case of a product catalog, secondaries might help the application scale its reads, given that most of the workload is read only. This allows the application to leverage multiple secondaries to increase read throughput. The trade off is that it might take some time for product document changes to replicate from the primary to the secondaries causing some stale reads. This might not be a problem but it’s important to be aware of the trade-off.
Sharding
Sharding the product category may not be effective and in most circumstances sharding will not add much in the way of performance as the workload is mostly read only. It could be better to approach scaling using secondary reads.
Performance
A simple exploration of the performance on a single machine with MongoDb 3.0 shows the difference between MMAP and WiredTiger for a narrow simulation using the schema simulation framework mongodb-schema-simulator.
Scenarios
MongoDb runs locally on a MacBook Pro Retina 2015 with ssd and 16 gb ram. The simulation runs with the following parameters against a single mongodb instance under osx 10.10 Yosemite.
Retrieve direct category children categories
| Parameters | Value |
|---|---|
| processes | 4 |
| poolSize per process | 50 |
| type | linear |
| Resolution in milliseconds | 1000 |
| Iterations run | 25 |
| Number of users reading | 1000 |
| Execution strategy | slicetime |
Retrieve category subtree
| Parameters | Value |
|---|---|
| processes | 4 |
| poolSize per process | 50 |
| type | linear |
| Resolution in milliseconds | 1000 |
| Iterations run | 25 |
| Number of users reading | 1000 |
| Execution strategy | slicetime |
MMAP
The MMAP engine is run using the default settings on MongoDB 3.0.1.
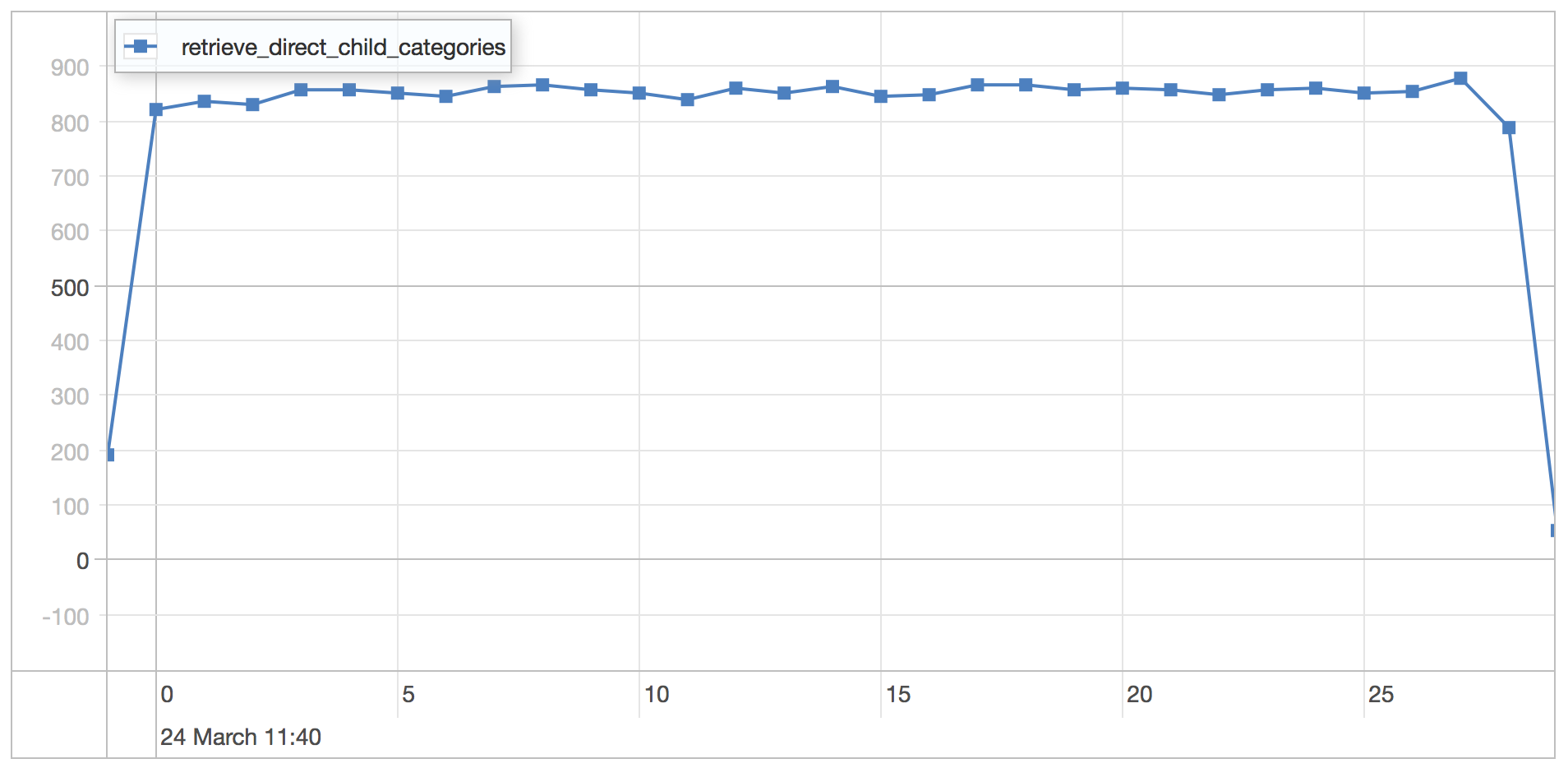
direct children results
| Statistics | Value |
|---|---|
| Runtime | 31.773 seconds |
| Mean | 0.954 milliseconds |
| Standard Deviation | 0.357 milliseconds |
| 75 percentile | 1.162 milliseconds |
| 95 percentile | 1.630 milliseconds |
| 99 percentile | 1.998 milliseconds |
| Minimum | 0.394 milliseconds |
| Maximum | 7.196 milliseconds |
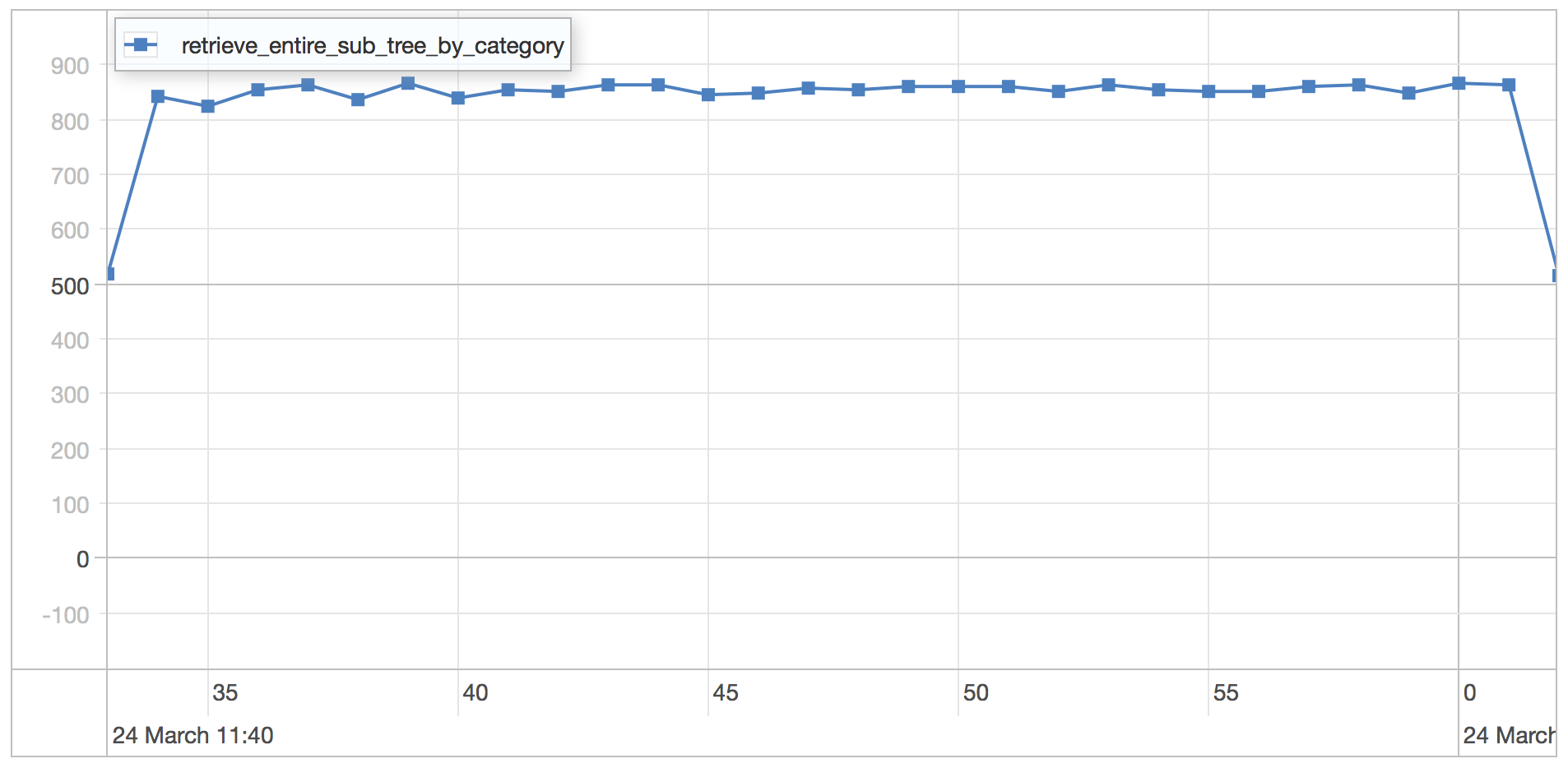
category subtree results
| Statistics | Value |
|---|---|
| Runtime | 31.617 seconds |
| Mean | 0.963 milliseconds |
| Standard Deviation | 0.413 milliseconds |
| 75 percentile | 1.159 milliseconds |
| 95 percentile | 1.669 milliseconds |
| 99 percentile | 2.104 milliseconds |
| Minimum | 0.379 milliseconds |
| Maximum | 8.818 milliseconds |
WiredTiger
The WiredTiger engine is run using the default settings on MongoDB 3.0.1.
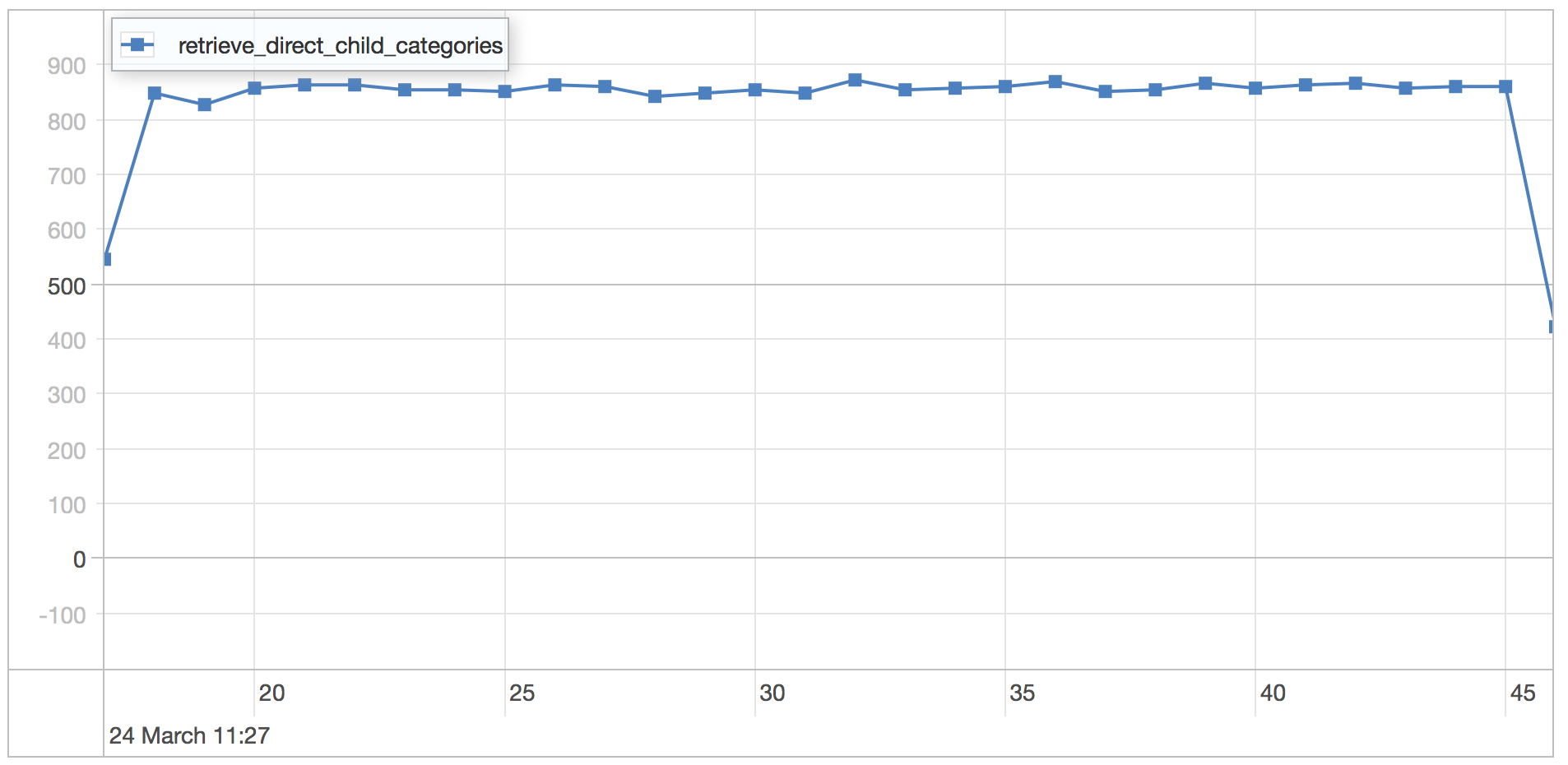
direct children results
| Statistics | Value |
|---|---|
| Runtime | 31.187 seconds |
| Mean | 0.998 milliseconds |
| Standard Deviation | 0.417 milliseconds |
| 75 percentile | 1.187 milliseconds |
| 95 percentile | 1.874 milliseconds |
| 99 percentile | 2.247 milliseconds |
| Minimum | 0.399 milliseconds |
| Maximum | 7.093 milliseconds |
category subtree results
| Statistics | Value |
|---|---|
| Runtime | 30.584 seconds |
| Mean | 0.992 milliseconds |
| Standard Deviation | 0.495 milliseconds |
| 75 percentile | 1.183 milliseconds |
| 95 percentile | 1.886 milliseconds |
| 99 percentile | 2.386 milliseconds |
| Minimum | 0.394 milliseconds |
| Maximum | 19.589 milliseconds |
As this is a read only workload the two storage engines are close in performance for the amount of load we applied to the MongoDB server instance.
Notes
One of the things to remember is that regular expression queries can only leverage indexes when they are case insensitive and convert to a simple start to end string match that can leverage an index. A more complex regular expression will cause a full index scan.
The following query will correctly use the index.
col.find({parent: /^\/electronics/}, {_id:0, parent:1, name:1}).explain();
The next query will cause an index scan due to it being a case insensitive regular expression.
col.find({parent: /^\/electronics/i}, {_id:0, parent:1, name:1}).explain();
If you can live with not retrieving the whole document for your category tree queries the covered indexes will allow you to avoid materializing the actual category documents into memory as the queries can be answered with the fields stored in the index itself.