- Schema Book
- Metadata
Metadata

Metadata is data that describes and provides information about other data. A classic example is the information about a digital photo, such as the ISO settings, resolution, pixel depth, exposure, camera settings, camera type and so on.
Let’s look at some sample metadata for an image.
| Field | Value |
|---|---|
| File name | img_1771.jpg |
| File size | 32764 Bytes |
| MIME type | image/jpeg |
| Image size | 480 x 360 |
| Camera make | Canon |
| Camera model | Canon PowerShot S40 |
| Image timestamp | 2003-12-14 12-01-44 |
| Image number | 117-1771 |
| Exposure time | 1⁄500 s |
| Aperture | F4.9 |
| Exposure bias | 0 EV |
| Flash | No, auto |
Each image might contain a different mix of fields depending on what features the camera supports. A cell phone might add GPS coordinates as metadata, while another might add more detailed flash information.
Obviously, it’s unfeasible to create an index for each possible metadata field. The schema we present in this chapter is optimized to allow for quick and efficient retrieval of documents by metadata fields.
Schema Observations
- Efficiently query in diverse sets of metadata tags, using a single index.
- All metadata keys are represented in the index, meaning it can get fairly large.
- Optimized for a read heavy workload.
Schema
In our schema we are going to leverage the fact that one can index arrays of objects easily in MongoDB. By using this ability, we can create a metadata field in a document, that can be efficiently queried.
{
"metadata": [
{"key": "File Name", "value": "img_1771.jpg"},
{"key": "File size", "value": 32764},
{"key": "MIME type", "value": "image/jpeg"},
{"key": "Image size", "value": {"width": 480, "height": 360}},
{"key": "Camera make", "value": "Canon"},
{"key": "Camera model", "value": "Canon PowerShot S40"},
{"key": "Image timestamp", "value": ISODate("2014-01-01T10:01:00Z")},
{"key": "Image number", "value": "117-1771"},
{"key": "Exposure time", "value": "1/500 s"},
{"key": "Aperture", "value": "F4.9"},
{"key": "Exposure bias", "value": "0 EV"},
{"key": "Flash", "value": "No, auto"}
]
}
Operations
To correctly query this schema, we need to learn about two query selection operators that allow us to match embedded documents in an array.
$all
The $all query operator is defined as selecting all the documents where the value of a field is an array that contains all the specified elements.
var col = db.getSisterDB("supershot").images;
col.findOne({tags: {$all: [ "appliance", "school", "book" ]}});
$elemMatch
The $elemMatch query operator matches more than one component within an array element.
var col = db.getSisterDB("supershot").images;
col.findOne({metadata: {$elemMatch: {key: "File Name", value: "img_1771.jpg"}}});
Let’s see how we can use the two operators to locate documents in our metadata schema.
The $elemMatch operator looks like the obvious first choice. However, the problem is that our metadata array is defined as objects that all have key and value fields. If you attempt to enter multiple matches using key and value in the $elemMatch only the last pair will be used.
If we wish to locate a photo that has MIME type equal to image/jpeg, and also Flash equal to No, auto we need to combine the two query operators $all and $elemMatch.
Let’s take a look at how to query our desired documents.
Querying Documents by Multiple metadata fields
var col = db.getSisterDB("supershot").images;
col.find({ metadata: { $all: [
{ "$elemMatch" : { key : "MIME type", value: "image/jpeg" } },
{ "$elemMatch" : { key: "Flash", value: "No, auto" } }
]}
}).toArray();
The first $elemMatch operator will locate all the documents with the MIME type equal to image/jpeg and then filter on the Flash key.
Indexes
To provide efficient retrieval of documents using the metadata schema, we need to create an index that allows us to optimize the query using the $elemMatch and $all operators.
For this we will need a compound index on the key and value fields inside the metadata array.
var col = db.getSisterDB("supershot").images;
db.images.ensureIndex({"metadata.key": 1, "metadata.value": 1});
Scaling
Secondary Reads
If the site is read heavy (say a photo album site), it might make sense to offload reads to secondary servers allowing the read load to be spread out.
Using secondary reads comes down to the level of acceptable latency for your application is willing to live with as there might be some delay between a write happening on a primary and the document being visible on the secondary.
Sharding
There is no efficient way to shard documents by a generic metadata key as the general nature of the schema precludes the usage of any of the fields in the metadata structure as a shard key.
The metadata would typically be part of the narrowing of a query and the shard key would be related to the purpose of the document containing the metadata structure.
Let’s take the image example and amend it with a user Id. We’ll would use the userId field as the shard key, route the query to a single shard and then narrow the query using the metadata fields.
{
, "userId": "olepeteraaa1"
, "metadata": [
{"key": "File Name", "value": "img_1771.jpg"},
{"key": "File size", "value": 32764},
{"key": "MIME type", "value": "image/jpeg"},
{"key": "Image size", "value": {"width": 480, "height": 360}},
{"key": "Camera make", "value": "Canon"},
{"key": "Camera model", "value": "Canon PowerShot S40"},
{"key": "Image timestamp", "value": ISODate("2014-01-01T10:01:00Z")},
{"key": "Image number", "value": "117-1771"},
{"key": "Exposure time", "value": "1/500 s"},
{"key": "Aperture", "value": "F4.9"},
{"key": "Exposure bias", "value": "0 EV"},
{"key": "Flash", "value": "No, auto"}
]
}
important
Using the userId as the shard key will ensure user specific images will be located on the same shard.
Performance
A simple exploration of the performance on a single machine with MongoDb 3.0 shows the difference between MMAP and WiredTiger for a narrow simulation using the schema simulation framework mongodb-schema-simulator.
Scenario
MongoDb runs on a MacBook Pro Retina 2013 with 512 GB ssd and 16 gb ram. The simulation runs with the following parameters against a single mongodb instance under osx 10.10 Yosemite.
| Parameters | Value |
|---|---|
| processes | 4 |
| poolSize per process | 50 |
| type | linear |
| Resolution in milliseconds | 1000 |
| Iterations run | 25 |
| Number of users querying using metadata per iteration | 1000 |
| Execution strategy | slicetime |
MMAP
The MMAP engine is run using the default settings on MongoDB 3.0.1.
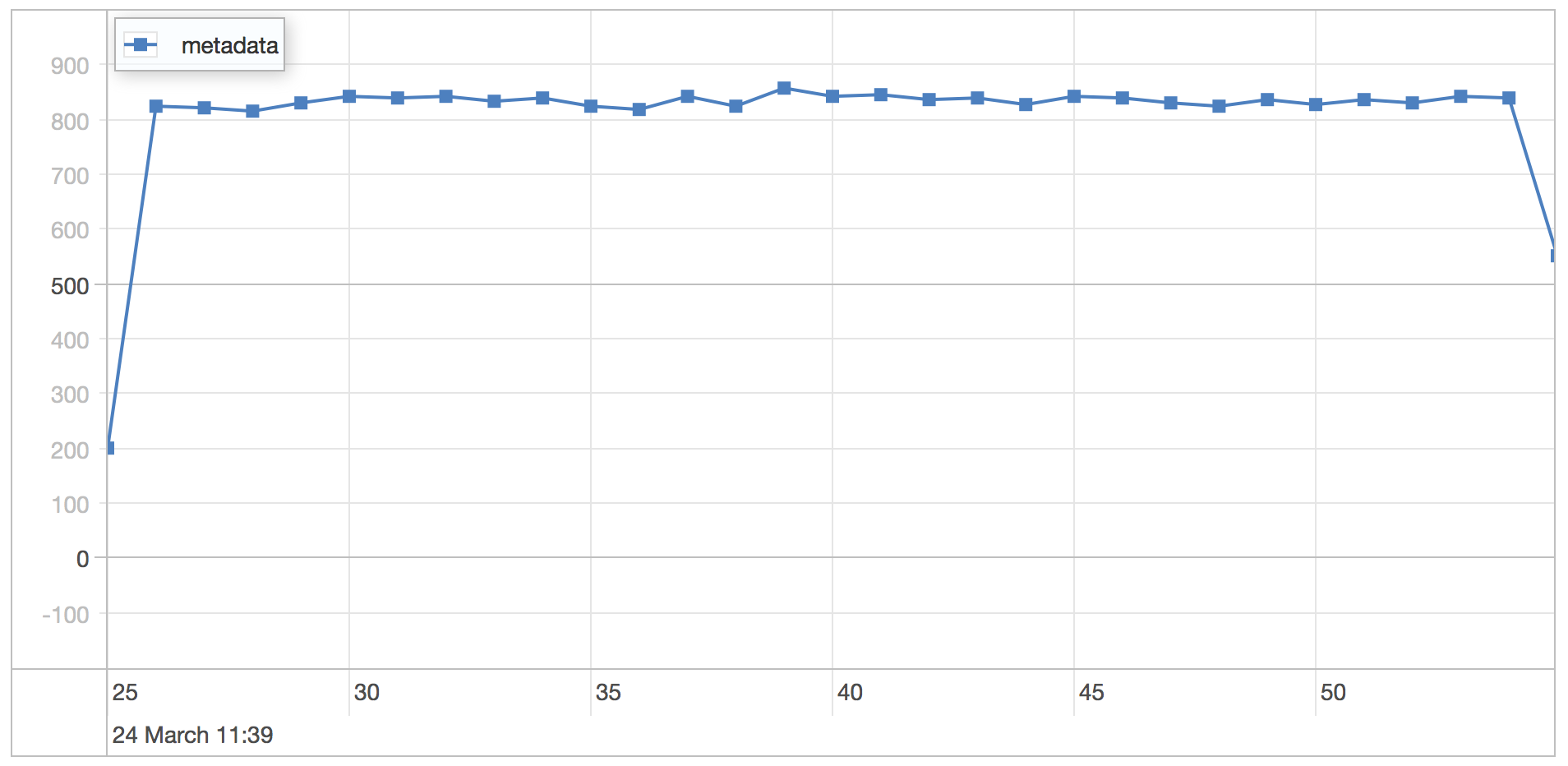
metadata scenario results
| Statistics | Value |
|---|---|
| Runtime | 40.874 seconds |
| Mean | 0.954 milliseconds |
| Standard Deviation | 0.291 milliseconds |
| 75 percentile | 1.187 milliseconds |
| 95 percentile | 1.367 milliseconds |
| 99 percentile | 1.619 milliseconds |
| Minimum | 0.441 milliseconds |
| Maximum | 4.885 milliseconds |
As we can see the 1000 users a second impacts the minimum and maximum as well as the average query time a fair bit.
WiredTiger
The WiredTiger engine is run using the default settings on MongoDB 3.0.1.
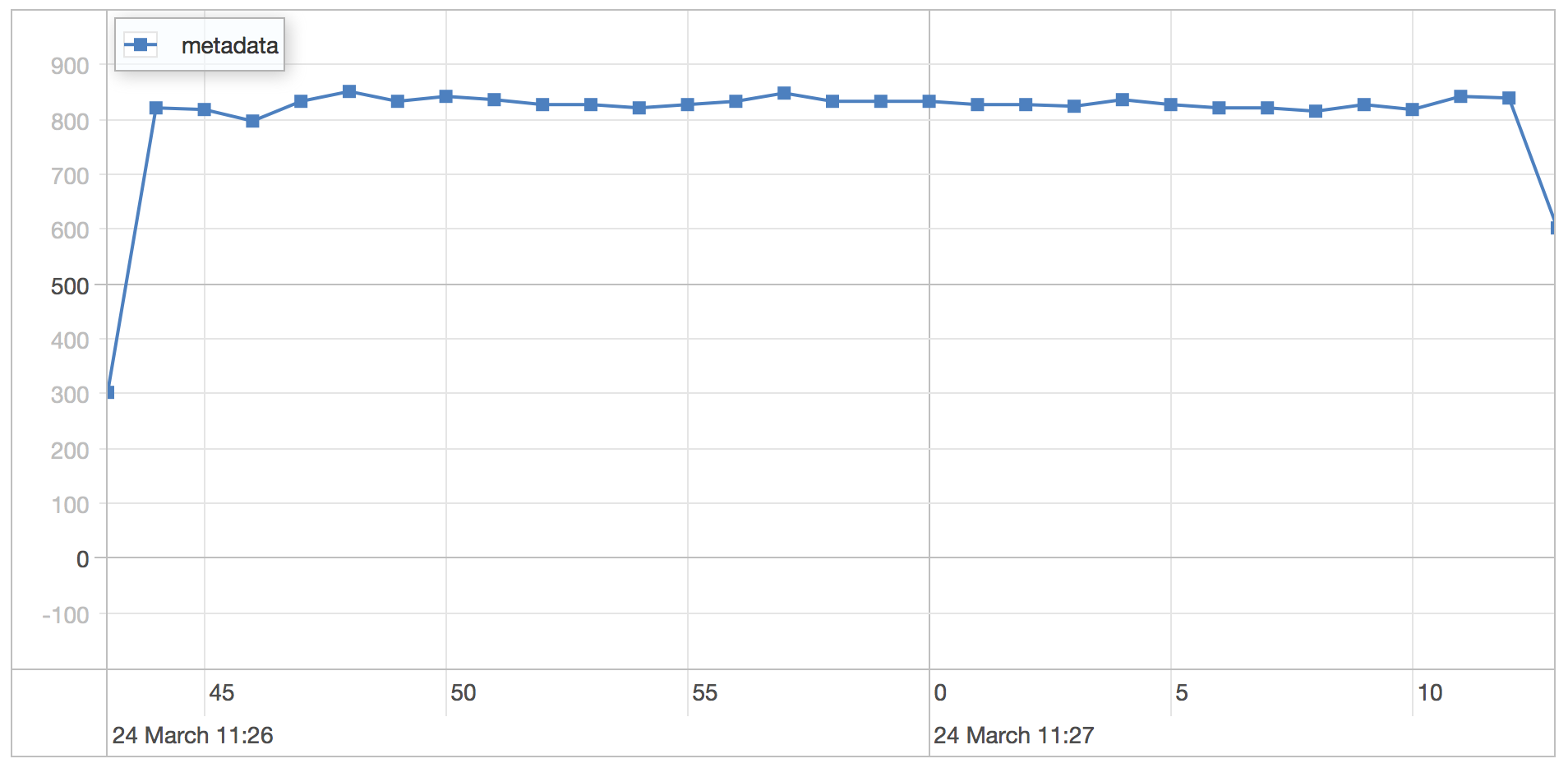
metadata scenario results
| Statistics | Value |
|---|---|
| Runtime | 40.01 seconds |
| Mean | 0.992 milliseconds |
| Standard Deviation | 0.318 milliseconds |
| 75 percentile | 1.232 milliseconds |
| 95 percentile | 1.431 milliseconds |
| 99 percentile | 1.706 milliseconds |
| Minimum | 0.484 milliseconds |
| Maximum | 9.827 milliseconds |
As expected there is not much difference between the MMAP and WiredTiger storage engines since this is mainly a read only workload.
Notes
important
Runtime versus Iterations
The number of iterations here is 25 meaning that every 1000 milliseconds we start up another 1000 users attempting to read metadata. We can see that the total runtime is around ~40 seconds instead of 25 seconds, which means we have surpased the maximum continous read capacity of the MongoDB instance on the used hardware. If we adjusted down the simulation load until the Runtime of the scenario was around ~25 seconds, we could estimate the maxmimum load our topology can handle.