- Schema Book
- Internationalization
Internationalization

In this internationalization example, we show a schema that might be useful for when you have to support multiple languages on an international site. We are going to use products and product categories in our example. This is a very simplified example and does not take into consideration more esoteric edge cases of i18 support.
Schema Observations
- Allow for single document reads, including all the translation information for efficient multi language support.
- The need to perform potentially mass updates can be costly if the translations are frequently changing.
Schema
Below is an example category document. The field names is an embedded document keyed by the language. In this case en-us means american english and the name of the category is car.
{
"_id" : 1
, "names" : {
"en-us" : "car"
}
}
The product contains all the categories as well, so that we can easily show the right name depending on the users preferred language. This is to optimize for single document retrieval avoid multiple round trips to the database. We will look at the trade off we make for this optimization later.
{
"_id" : 1
, "name" : "car"
, "cost" : 100
, "currency" : "usd"
, "categories" : [{
"_id" : 1
, "names" : { "en-us" : "car" }
} ]
}
Operations
Add a new translation to a category
We are going to add the de-de local to the car category shown above. For simplicity’s sake we will assume this category is identified by the _id field set to the value 1.
{lang=“js”, linenos=on, title=“Example 1: Add a new translation”}
var categoryId = 1;
var categories = db.getSisterDB("shop").categories;
var products = db.getSisterDB("shop").products;
categories.update({
_id: categoryId
}, {
$set: {
"categories.$.names.de-de": 'auto'
}
});
products.update({
"categories._id": categoryId
}, {
$set: {
"categories.$.names.de-de": 'auto'
}
})
In the first step, we update the category by adding the new de-de local to the document.
In the second step, we need to update all the caches of all documents that contain the car category. The update statement looks for all products where the categoires._id field matches categoryId. Then, on the first matching document for that categoryId, it adds the new local.
Removing a translation from a category
If we wish to remove a translation from a category, we need to first remove it from the category and then update all the product caches.
{lang=“js”, linenos=on, title=“Example 1: Remove a translation”}
var categoryId = 1;
var categories = db.getSisterDB("shop").categories;
var products = db.getSisterDB("shop").products;
categories.update({
_id: categoryId
}, {
$unset: {
"categories.$.names.de-de": 'auto'
}
});
products.update({
"categories._id": categoryId
}, {
$unset: {
"categories.$.names.de-de": 'auto'
}
})
Just as when adding it, the only change is that we are using the $unset update operator to remove the field from the embedded documents.
Indexes
In this example there are special indexes used other than the _id index.
Scaling
Secondary Reads
If the site is read heavy (say a product catalog), it might make sense to offload reads to secondary servers to scale reading. It comes down to the application’s acceptable latency level as there might be some delay between a write happening on a primary until it’s been replicated across to the secondary.
Sharding
The multi language pattern does not really benefit from sharding. It’s more likely that you would shard the collections based on other criteria.
Performance
There is a very obvious trade off being made here. We are exchanging the costs of updating all the products each time we add or remove a local against the need to perform multiple reads on the categories collection. Since adding new translations are not likely to happen constantly, the added updates to the products collection are insignificant against the benefit of performing single document reads when retrieving the product documents.
A simple exploration of the performance on a single machine with MongoDb 3.0 shows the difference between MMAP and WiredTiger for a narrow simulation using the schema simulation framework mongodb-schema-simulator.
Scenarios
MongoDb runs locally on a MacBook Pro Retina 2015 with ssd and 16 gb ram. The simulation runs with the following parameters against a single mongodb instance under osx 10.10 Yosemite.
Add a local to a category
| Parameters | Value |
|---|---|
| processes | 4 |
| poolSize per process | 50 |
| type | linear |
| Resolution in milliseconds | 1000 |
| Iterations run | 25 |
| Number of users adding locals to category iteration | 1000 |
| Execution strategy | slicetime |
Remove a local from a category
| Parameters | Value |
|---|---|
| processes | 4 |
| poolSize per process | 50 |
| type | linear |
| Resolution in milliseconds | 1000 |
| Iterations run | 25 |
| Number of users adding locals to category iteration | 1000 |
| Execution strategy | slicetime |
MMAP
The MMAP engine is run using the default settings on MongoDB 3.0.1.
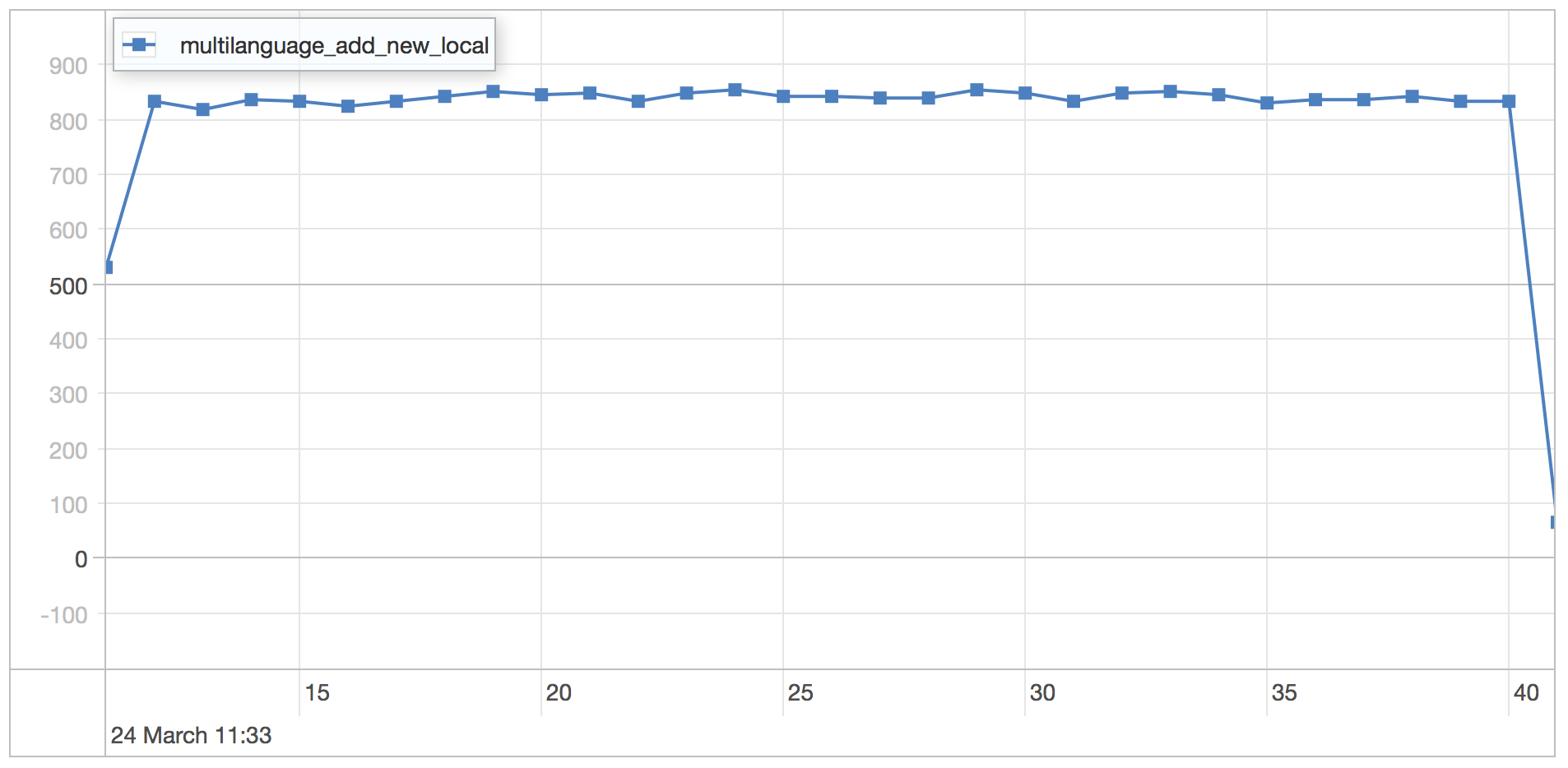
add local to category scenario results
| Statistics | Value |
|---|---|
| Runtime | 30.898 seconds |
| Mean | 0.676 milliseconds |
| Standard Deviation | 0.202 milliseconds |
| 75 percentile | 0.716 milliseconds |
| 95 percentile | 0.865 milliseconds |
| 99 percentile | 1.446 milliseconds |
| Minimum | 0.391 milliseconds |
| Maximum | 6.839 milliseconds |
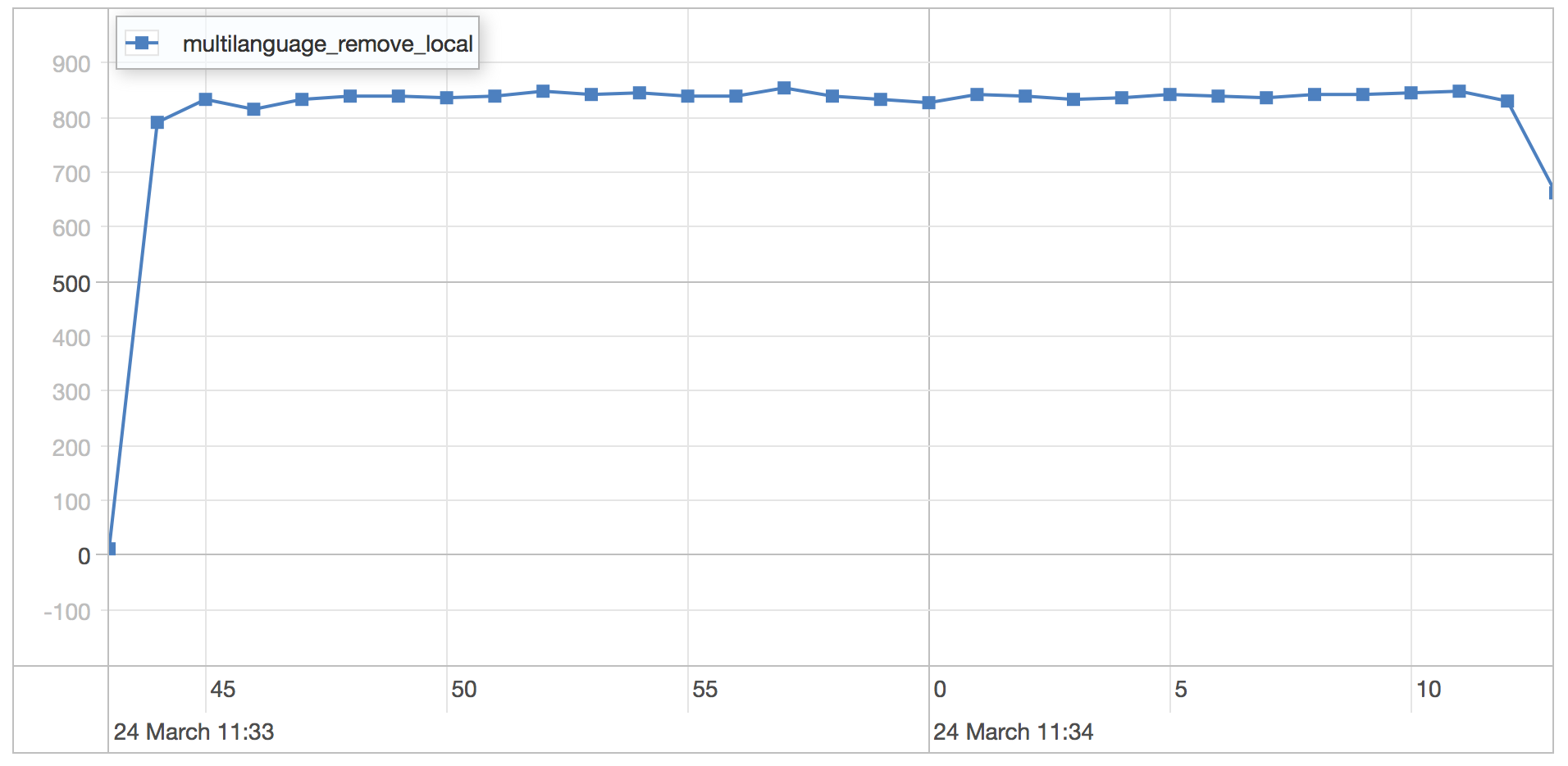
remove local from category scenario results
| Statistics | Value |
|---|---|
| Runtime | 31.037 seconds |
| Mean | 0.675 milliseconds |
| Standard Deviation | 0.185 milliseconds |
| 75 percentile | 0.715 milliseconds |
| 95 percentile | 0.867 milliseconds |
| 99 percentile | 1.418 milliseconds |
| Minimum | 0.403 milliseconds |
| Maximum | 5.882 milliseconds |
As expected the performance is similar because the patterns are similar. We would expect the performance to be tied to the amount of documents that need to be updated when a new local is added to a category.
WiredTiger
The WiredTiger engine is run using the default settings on MongoDB 3.0.1.
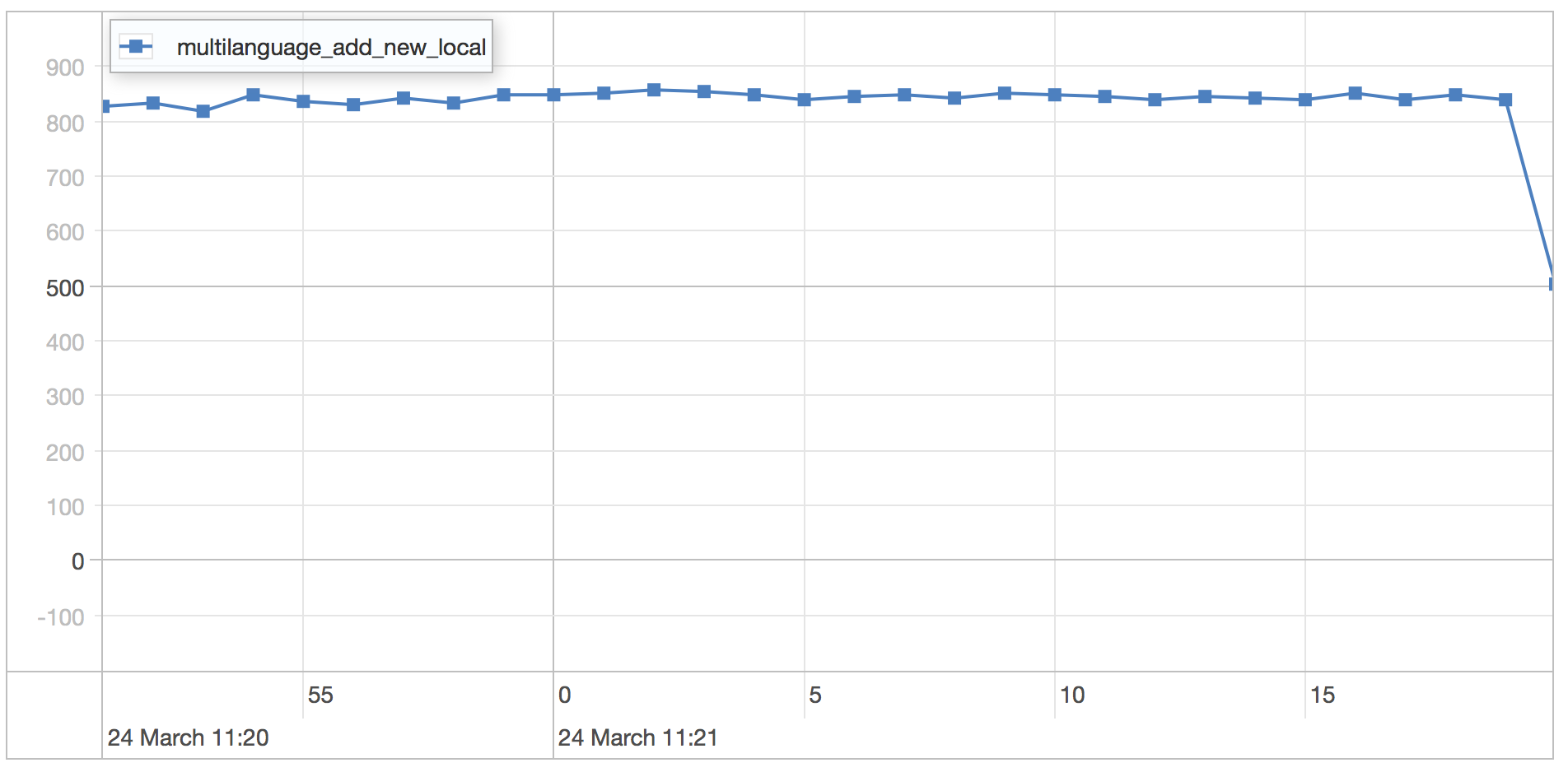
add local to category scenario results
| Statistics | Value |
|---|---|
| Runtime | 30.681 seconds |
| Mean | 0.693 milliseconds |
| Standard Deviation | 0.219 milliseconds |
| 75 percentile | 0.73 milliseconds |
| 95 percentile | 0.889 milliseconds |
| 99 percentile | 1.582 milliseconds |
| Minimum | 0.409 milliseconds |
| Maximum | 7.157 milliseconds |
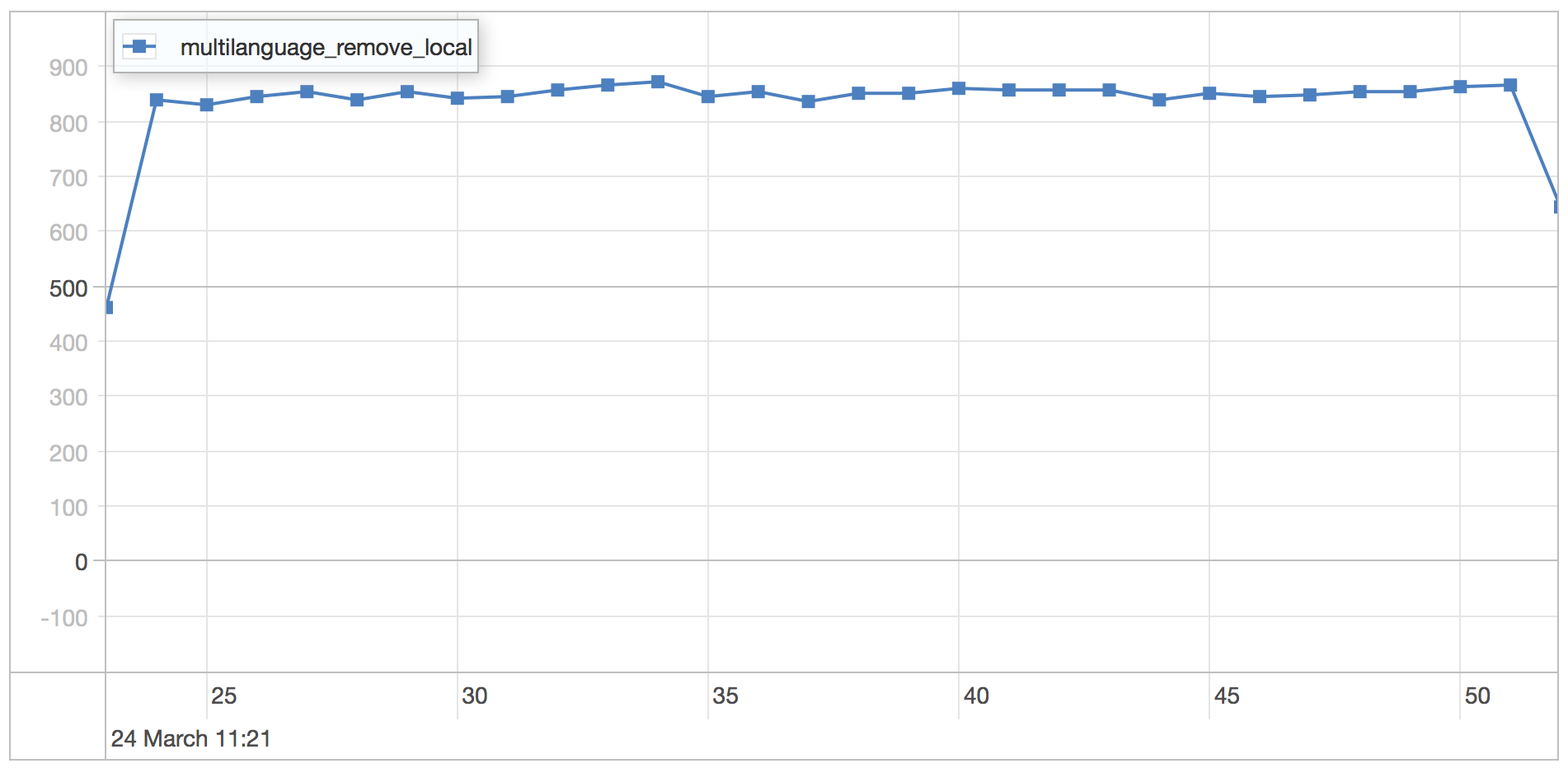
remove local from category scenario results
| Statistics | Value |
|---|---|
| Runtime | 30.404 seconds |
| Mean | 0.913 milliseconds |
| Standard Deviation | 0.337 milliseconds |
| 75 percentile | 1.145 milliseconds |
| 95 percentile | 1.316 milliseconds |
| 99 percentile | 1.763 milliseconds |
| Minimum | 0.409 milliseconds |
| Maximum | 7.938 milliseconds |
WiredTiger is a bit slower than MMAP for this schema as it involves a lot of in place updates that causes the storage engine to rewrite the entire document.
Notes
It’s important to consider the trade off of caching vs performing multiple queries. In this case it’s pretty obvious the caching strategy will pay off but there might be situations where it doesn’t.
Let’s say you are caching stock ticker prices in a portfolio object where the stock ticker is constantly changing. The constant changes and required writes will offset any benefit of caching the latest stock prices in the portfolio document. In this case, it’s better to fetch the latest stock prices from a the prices collections instead.
tip
High rate of change
One more thing to consider is that if you find your application is constantly adding new categories or translations it might be beneficial to duplicate the product information making an identical document for each language allowing for single document reads for any language and avoiding massive updates across all possible products.