- Schema Book
- Sharding
Sharding
Sharding is one of the more complex features provided by MongoDB and getting comfortable with it can take some time. Sharding is a mechanism for scaling writes by distributing them across multiple shards. Each document contains an associated shard key field that decides on which shard the document lives.
Sharding Topology
In MongoDB sharding happens at the collection level. That is to say you can have a combination of sharded and unsharded collections. Let’s look at a simple example topology.
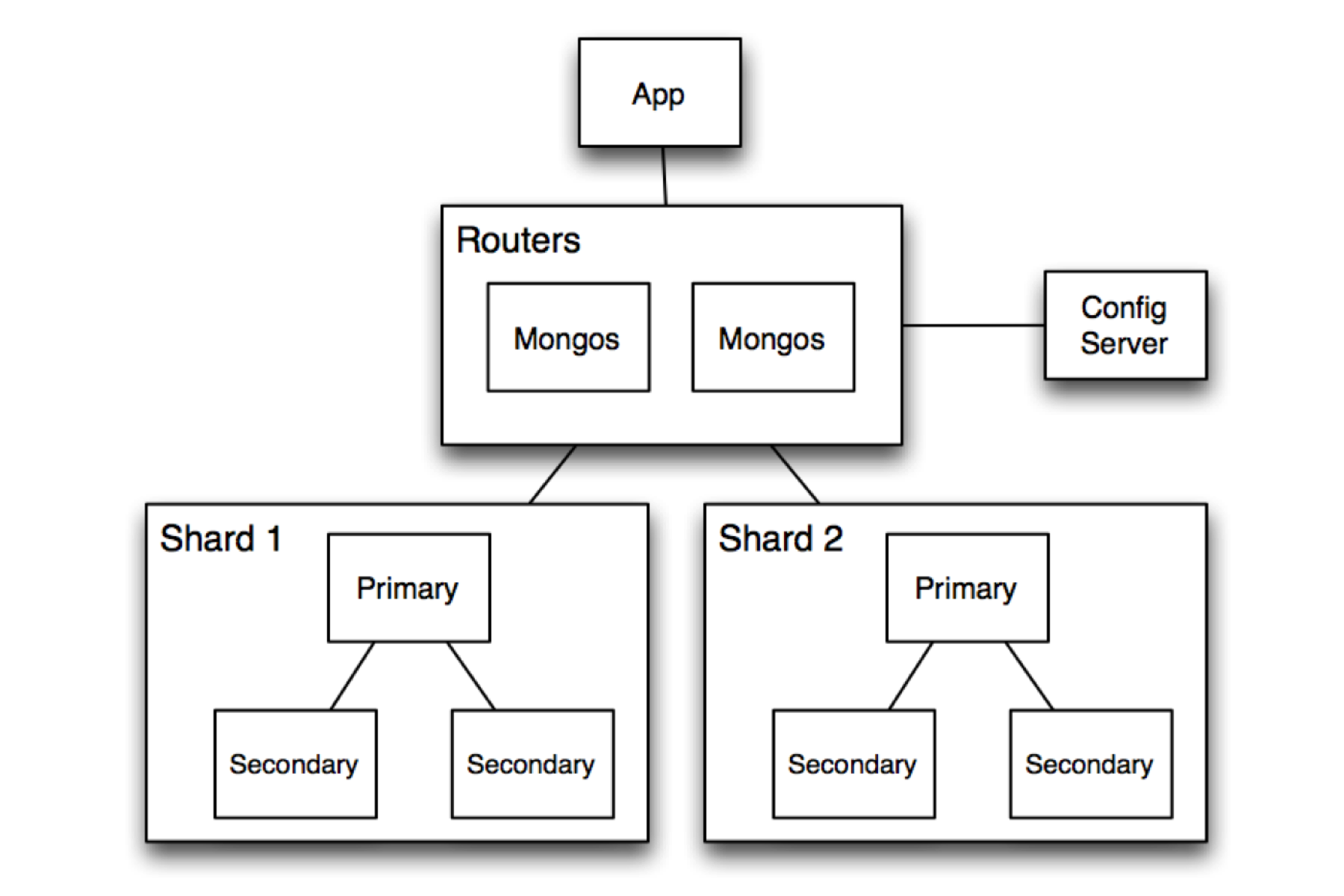
The application does not directly talk to the shards but instead talks through the sharding proxy Mongos. Mongos is responsible for the routing of writes and queries to the shards.
When to Shard
One of the typical errors people commit is to shard too early. The reason this can be a problem, is that sharding requires the developer to pick a shard key for distribution of the writes and it’s easy to pick the wrong key early on due to not knowing how the data will be accessed over time.
This can lead reads to be inefficiently spread out across shards causing unnecessary IO and CPU usage in order to retrieve the data. Once the collection is sharded, it can be very time consuming to undo it, as all the data will have to be migrated from one sharded collection to another by reinserting all the documents into the new collection.
That said, let’s look at some reason you might want to Shard.
Your Working Set no longer fits in the memory of your server. In this case, sharding can help make more of your Working Set stay in memory by pooling the RAM of all the shards. If you have a 20GB Working Set on a 16GB machine, sharding can split this across 2 machines for a total of 32GB of RAM available, potentially keeping all of the data in RAM and avoiding disk IO.
Scaling the write IO. You need to perform more write operations than what a single server can handle. By
Shardingyou can scale out the writes across multiple computers, increasing the total write throughput.
Choosing a Shard Key
It’s important to pick a Shard key based on the actual read/write profile of your application to avoid inefficient queries and write patterns. There are a couple of tips that can help in the quest to identify the right shard key.
Easily Divisible Shard Key (Cardinality)
When discussing cardinality in the context of MongoDB, we refer to the ability to partition data into chunks distributed across all the shards. Let’s look at some example shard keys.
Picking the state field as a shard key
In our documents the state field contains the US state for a specific address. This field is considered low cardinality, as all documents containing the same state will have to reside on the same shard. Since the key space for states is a limited set of values, MongoDB might end up distributing the data unevenly across a small set of fixed chunks. This might cause some unintentional side effects.
- It could lead to un-splittable chunks that could cause migration delays and unnecessary IO due to MongoDB attempting to split and migrate chunks.
- The un-splittable chunks might make it difficult to keep the shards balanced,causing load distribution to be uneven across the shards.
- If the number of values map to a maximum of un-splittable chunks, adding more shards might not help as there are fewer chunks available than shards. Due to the chunks being un-splittable, we cannot leverage the additional shards.
Picking the post code field as a shard key
If we pick the post code field as a shard key, the number of possible post codes is higher than when using the state state field. So the shard key is considered to have a higher cardinality than when using the state field. However the number of post codes does not completely mitigate the situation of un-splittable chunks. As one can imagine, one post code has a lot more associated addresses, which could make that specific chunk un-splittable.
Picking the phone number field as a shard key
The phone number field has high cardinality as there might be few users mapping to a specific phone number. This will make it easy for MongoDB to split chunks, as chunks won’t be made up of documents that map to the same shard key, avoiding the possible problem of using the state field.
tip
Cardinality
Always consider the number of values your shard key can express. A sharding key that has only 50 possible values, is considered low cardinality, while one that might be able to express several million values might be considered a high cardinality key. High cardinality keys are preferable to low cardinality keys to avoid un-splittable chunks.
High Randomness Shard Key (Write Scaling)
A key with high randomness will evenly distribute the writes and reads across all the shards. This works well if documents are self contained entities such as Users. However queries for ranges of documents, such as all users with ages less than 35 years will require a scatter gather query where all shards are queried and a merge sort is done on Mongos.
Single Shard Targeted Key (Query Isolation)
Picking a shard key, that groups the documents together will make most of the queries go to a specific Shard. This can avoid scatter gather queries. One possible example might be a Geo application for the UK, where the first part of the key includes the postcode and the second is the address. Due to the first part of the shard key being the postcode, all documents for that particular sort key will end up on the same Shard, meaning all queries for a specific postcode will be routed to a single Shard.
The UK postcode works as it has a lot of possible values due to the resolution of postcodes in the UK. This means there will only be a limited amount of documents in each chunk for a specific postcode. However, if we were to do this for a US postcode we might find that each postcode includes a lot of addresses causing the chunks to be hard to split into new ranges. The effect is that MongoDB is less able to spread out the documents and in the end this impacts performance.
Routing Shard Keys
Depending on your Shard key the routing will work differently. This is important to keep in mind as it will impact performance.
| Type Of Operation | Query Topology |
|---|---|
| Insert | Must have the Shard key |
| Update | Can have the Shard key |
| Query with Shard Key | Routed to nodes |
| Query without Shard Key | Scatter gather |
| Indexed/Sorted Query with Shard Key | Routed in order |
| Indexed/Sorted Query without Shard Key | Distributed sort merge |
Inbox Example
Imagine a social Inbox. In this case we have two main goals
- Send new messages to it’s recipients efficiently
- Read the Inbox efficiently
We want to ensure we meet two specific goals. The first one is to write to multiple recipients on separate shards thus leveraging the write scalability. For for a user to read their email box, one wants to read from a single shard avoid scatter/gather queries.
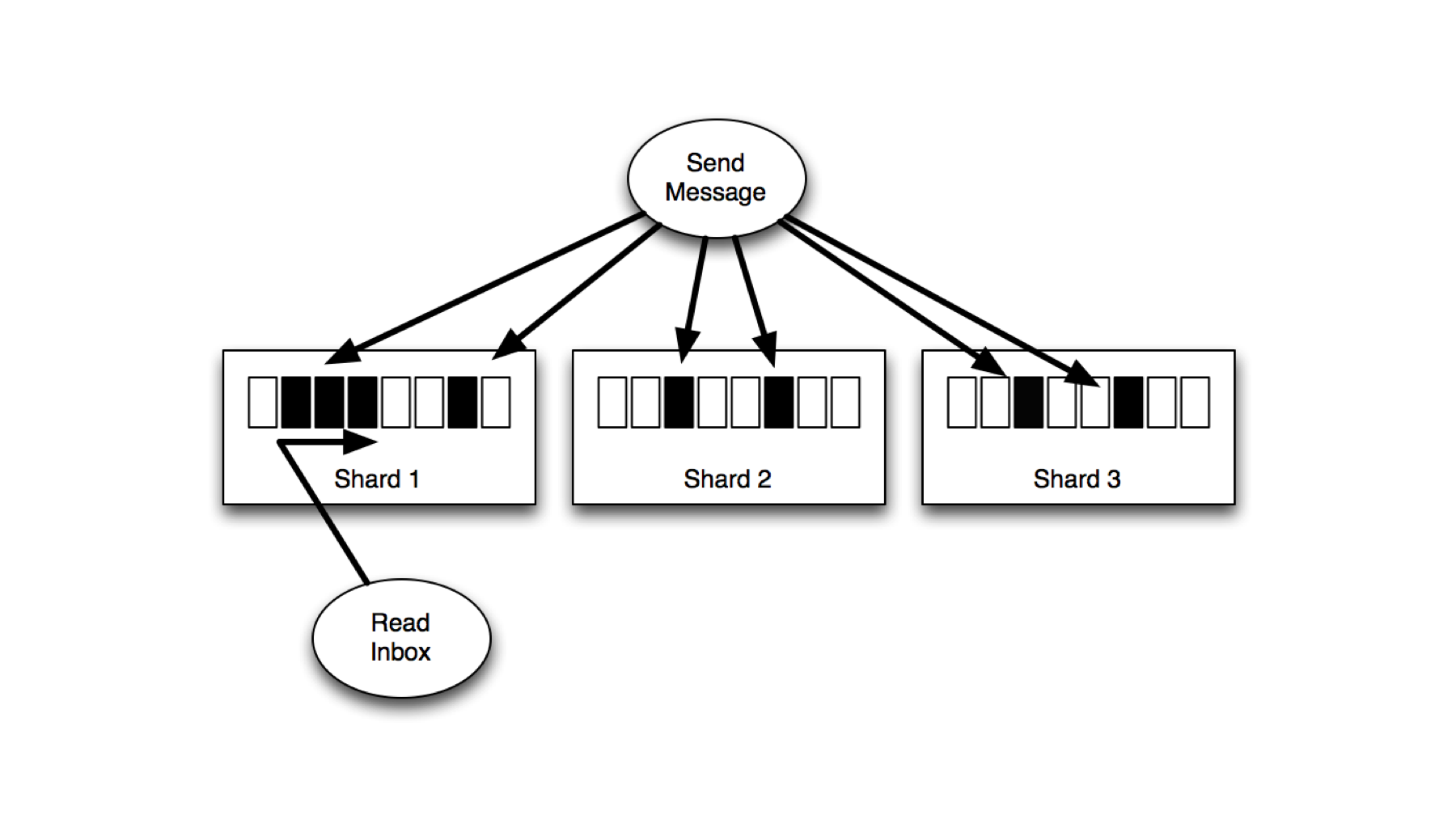
How does one go about getting the correct shard key? Let’s assume we have two collections inbox and users, in our social database.
var db = db.getSisterDB('social');
db.shardCollection('social.inbox', {owner: 1, sequence: 1});
db.shardCollection('social.users', {user_name: 1});
Let’s write and read to the collections with some test data to show how we can leverage the sharding.
var db = db.getSisterDB('social');
var msg = {
from: 'Christian',
to: ['Peter', 'Paul'],
sent_on: new Date(),
message: 'Hello world'
}
for(var i = 0; i < msg.to.length; i++) {
var result = db.users.findAndModify({
query: { user_name: msg.to[i] },
update: { '$inc': {msg_count: 1} },
upsert: true,
new: true
})
var count = result.msg_count;
var sequence_number = Math.floor(count/50);
db.inbox.update({ owner: msg.to[i], sequence: sequence} ),
{ $push: {messages: msg} },
{ upsert:true });
}
db.inbox.find({owner: 'Peter'})
.sort({sequence: -1})
.limit(2);
The first part delivers the message to all its recipients. First, it updates the message count for the recipient and then pushes the message to the recipient’s mailbox (which is an embedded document). The combination of the Shard key being {owner: 1, sequence: 1}, means that all new messages get written to the same chunk for a specific owner. The Math.floor(count/50) generation will split up the inbox into buckets of 50 messages in each.
This last aspect means that the read will be routed directly to a single chunk on a single Shard, avoiding scatter/gather and speeding up retrieval.
Multiple Identities Example
What if we need to lookup documents by multiple different identities like a user name, or an email address?
Take the following document:
var db = db.getSisterDB('users');
db.users.insert({
_id: 'peter',
email: 'peter@example.com'
})
If we shard by _id, it means that only _id queries will be routed directly to the right shard. If we wish to query by email we have to perform a scatter/gather query.
There is a possible solution called document per identity. Let’s look at a different way of representing the information.
var db = db.getSisterDB('users');
db.identities.ensureIndex({ identifier: 1 }, { unique: true });
db.identities.insert({
identifier: {user: 'peter'}, id: 'peter'});
db.identities.insert({
identifier: {email: 'peter@example.com', user: 'peter'},
id: 'peter'});
db.shardCollection('users.identities', {identifier: 1});
db.users.ensureIndex({ _id: 1}, { unique: true });
db.shardCollection('users.users'. { _id: 1});
We create a unique index for the identities table to ensure we cannot map two entries into the same identity space. Using the new compound shard key we can retrieve a user by its email by performing two queries. Let’s see how we can look up the user document of the user with the email address of peter@example.com.
var db = db.getSisterDB('users');
var identity = db.identities.findOne({
identifier: {
email: 'peter@example.com'}});
var user = db.users.find({ _id: identity.id });
The first query locates the identity using the email, which is a routed query to a single shard. The second query uses the returned identitiy.id field to retrieve the user by the shard key.
Sharding Anti-Patterns
There are a couple of sharding anti-patterns that you should keep in mind to avoid some of the more common pitfalls.
Monotonically increasing shard key
A monotonically increasing shard key, is an increasing function such as a counter or an ObjectId. When writing documents to a sharded system using an incrementing counter as it’s shard key, all documents will be written to the same shard and chunk until MongoDB splits the chunk and attempts to migrate it to a different shard. There are two possible simple solutions to avoid this issue.
Hashing the shard key
From MongodDB 2.4, we can tell MongoDB to automatically hash all of the shard key values. If we wanted to create documents where the shard key is _id with an ObjectId, we could shard the collection using the following options.
sh.shardCollection( "users.users", { _id: "hashed" } )
Pre-split the chunks
The second alternative is to pre-split the shard key ranges and migrate the chunks manually, ensuring that writes will be distributed. Say you wanted to use a date timestamp as a shard key. Everyday you set up a new sharded system to collect data and then crunch the data into aggregated numbers before throwing away the original data.
We could pre-split the key range so each chunk represented a single minute of data.
/ first switch to the data DB
use data;
// now enable sharding for the data DB
sh.enableSharding("data");
// enable sharding on the relevant collection
sh.shardCollection("data.data", {"_id" : 1});
// Disable the balancer
sh.stopBalancer();
Let’s split the data by minutes.
/ first switch to the admin db
use admin;
// 60 minutes in one hour, 24 hours in a day
var numberOfMinutesInDay = 60*24;
var date = new Date();
date.setHours(0);
date.setMinutes(0)
date.setSeconds(0);
// Pre-split the collection
for(var i = 0; i < numberOfMinutesInDay; i++) {
db.runCommand({ split: "data.data",
middle: {_id: date}
});
date.setMinutes(date.getMinutes() + 1);
}
Finally re-enable the balancer and allow MongoDB to start balancing the chunks to the shards.
// Enable the balancer
sh.startBalancer();
You can monitor the migrations by connecting to mongos, using the mongo shell and executing the sh.status() command helper to view the current status of the sharded system.
The goal of pre-splitting the ranges is to ensure the writes are distributed across all the shards even though we are using a monotonically increasing number.